흔히 RAM을 메모리라고 지칭하기도 하는데 정확한 범주에서는 RAM의 정의가 임의로 접근 가능한 메모리이기 때문에 메모리, SSD, HDD 등과 같은 보조기억장치도 포함하는 개념이다. 여기서 특징은 메모리는 휘발성 메모리이고, 디스크는 비휘발성 메모리라는 것이다. 이 글에서는 메모리에 대해 주로 다루고자 한다.
RAM(Random Access Memory): 임의 접근 메모리
VM(Volatile Memory): 휘발성 메모리
NVM(Non-Volatile Memory): 비휘발성 메모리
1-2. 세부 컴포넌트
데이터를 저장하는 DRAM과 이를 연산하는 CPU, 이들 간의 데이터를 전달할 수 있는 인터페이스들까지 우리는 메모리라 일컫는다. DRAM은 메모리 모듈에 구성되어 마더보드와 연결되고, 마더보드는 CPU와 메모리 모듈이 데이터를 주고 받을 수 있도록 하고, 전원을 공급하는 역할을 한다. 각 인터페이스는 다음과 같다.
마더보드: 하드웨어 구성 요소들을 연결하는 플랫폼으로써 전원을 공급하고 시스템 버스를 통해 데이터 및 제어 신호를 전달하여 상호 작용을 가능하도록 한다.
메모리 컨트롤러: CPU 내부에 위치한 하드웨어로 코어의 메모리 엑세스 및 제어를 담당한다.
메모리 버스: 마더 보드에 존재하며 CPU와 메모리 간의 데이터 및 제어 신호를 전송하는 통로이다.
메모리 모듈: 흔히 말하는 DRAM 찹을 탑재하는 모듈로써 메모리 버스에 직접 연결되어 CPU의 메모리 컨트롤러를 통해 데이터를 주고 받는다.
그림 1. Memory overview
#2 메모리 컨트롤러
2-1. 위치 변화
모놀리식 구조의 컴퓨터 구조에서 메모리 컨트롤러는 FSB를 통해 마더보드 내부의 노스브릿지와 연결되어 CPU가 메모리 컨트롤러로 요청을 보내면 메모리 컨트롤러가 DIMM과의 상호 작용을 통해 데이터를 전송하는 방식의 구조였다. 하지만 마이크로프로세서 구조로 넘어가면서 메모리 레이턴시를 줄이기 위해 CPU 내부로 메모리 컨트롤러의 위치를 옮겨가게 되었다. 이는 성능의 향상을 가져오기도 했지만 반대로 메모리가 CPU 타입에 귀속되는 결과도 가져오게 되었다.
2-2. 채널
메모리 채널은 메모리 컨트롤러가 메모리 모듈과 연결되는 통로로 하낭의 채널은 하나의 메모리 모듈과 연결된다. 메모리 채널의 대역폭은 메모리 채널의 전송 속도와 비트 수를 곱한 것과 같다. 대역폭을 쉽게 늘리기 위한 수단으로 멀티/코어/옥타 채널도 요즘은 많이 사용한다.
그림 2. Quad channel overview
#3 DIMM (Dual In-line Memory Module)
3-1. 구성 요소
RCD: 시스템 클럭 신호를 버퍼링하여 CPU와 DIMM 사이의 연산 상호작용을 수행하는 칩
DRAM: 동적 임의 접근 메모리
Rank: 여러 DRAM 칩을 묶어 한 Rank를 구성
Bank: DRAM 칩의 물리적인 한 섹션
Row: bank 내의 행
Col: bank 내의 열
3-2. 동작
비트 수에 따라 주소 구성 달라짐 페이징 기법에서 메모리 프레임 번호가 row/col + rank + bank + channel의 조합
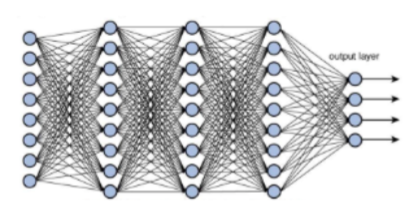
인공신경망(Arificial Neural Network)는 생물학적 뉴런이 작동하는 방식에서 영감을 받은 수학적 모델이다. 이 모델은 입력 데이터를 받아 처리하여 출력값을 반환하는 것을 목적으로 한다. 인공 신경망은 여러 개의 계층으로 구성되며, 각 계층은 뉴런이라 불리는 단위로 구성 된다.
1-2. 다층 퍼셉트론
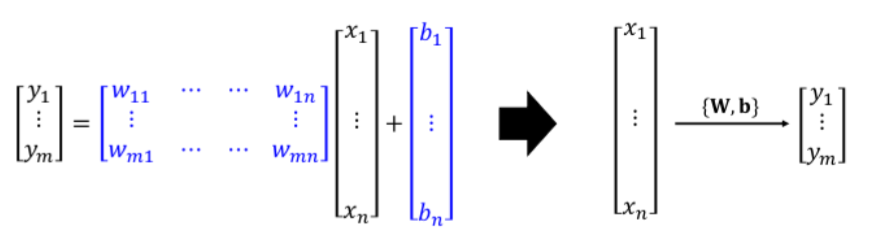
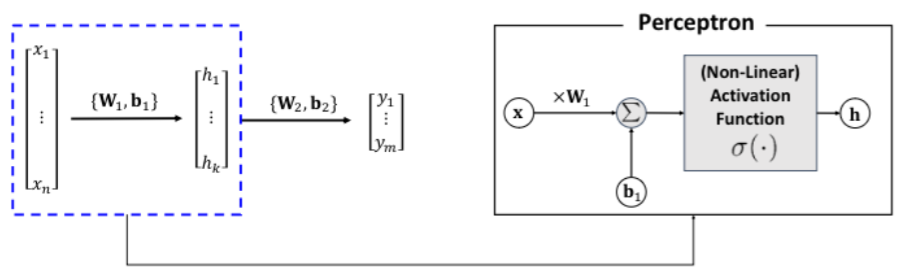
인공신경망의 가장 기본적인 형태는 입력 계층과 출력 계층으로 이루어진 단순 퍼셉트론이다. 여기서 (여러 개의) 은닉 계층이 추가되면 이를 다층 퍼셉트론(Multilayer perceptron, MLP)라 하며, 각 뉴런은 입력과 가중치를 곱하고 편향을 더한 후 활성화 함수를 적용하여 출력을 생성한다. 이런 식으로 입력에서 출력까지 데이터가 전달되며, 학습 알고리즘을 사용하여 신경망이 원하는 출력에 가깝게 학습된다. 우리가 흔히 말하는 딥러닝의 과정이 다층 퍼셉트론인 것이다.
그림 1. 신경망과 인공신경망
#2 모델
2-1. 기본 형태
인공신경망은 주어진 입력값에 대해 원하는 출력을 생성하는 수학적 모델이다. 인공신경망의 가장 기본적이고 단순한 형태는 선형회귀로 볼 수 있다. 선형회귀는 하나의 계층으로 이루어져 선형 함수를 학습하는 모델으로 다음 입력값을 선형 모델을 통해 예측할 수 있다.
그림 2. 선형 함수 예
일반적인 모델의 학습은 활성화 함수 -> 손실 함수 -> 최적화 -> 정규화의 과정을 따르며 활성화 함수 단계를 제외 하면 앞서 설명했던 선형회귀와 같은 순서이다. 순서는 엄밀하게 고정되지 않고 유연하게 바뀔 수 있으며, 한 알고리즘이 다른 단계를 포함하기도 한다.
2-2. 활성화 함수
하지만 실제로 인공신경망이 학습하는 것은 단순히 점 사이의 선을 학습하는 것이 아닌 패턴이나 이미지, 음성, 텍스트 등 다양한 분야에서 학습을 시도한다. 하지만 단일 계층의 선형함수의 형태로는 이러한 학습이 어렵기 때문에 여러 계층으로 비선형 함수를 학습할 수 있어야 한다. 이를 위해 다층 퍼셉트론에서는 비선형 함수를 학습할 수 있도록 선형 함수로 변환하는 역할인 활성화 함수를 사용하고, 변환된 선형 함수들을 다층으로 학습하여 원하는 출력값을 생성하도록 한다.
그림 3. 활성화 함수
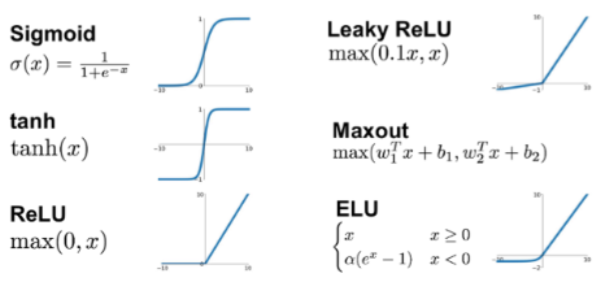
다양한 활성화 함수의 예시는 다음과 같으며 각각의 원리를 통해 비선형 변환을 수행한다.
Sigmoid: 입력값을 0과 1 범위로 압축, 입력 값이 매우 크거나 작을 때 경사가 급격하게 감소하여 그래디언트 손실 문제가 발생, 주로 이진 분류 문제에서 출력층의 활성화 함수로 사용
Hyperbolic Tangent Function (tanh): 입력값을 -1과 1 범위로 압축, 입력 값이 매우 크거나 작을 때 경사가 급격하게 감소하여 그래디언트 손실 문제가 발생, 주로 RNN이나 은닉층의 활성화 함수로 사용
Rectified Linear Unit (ReLU): 입력값이 0보다 크면 그대로 반환하고 0보다 작으면 0으로 변환, 학습 속도가 매우 빠르고 구현이 간단하여 일반적으로 은닉층의 활성화 함수로 많이 사용, 입력이 음수일 때 출력이 0이 되어 dying ReLU 문제 발생
Leaky ReLU: 입력값이 0보다 크면 그대로 반환하고 0보다 작으면 작은 양수로 반환, 일반적으로 -0.01과 같은 기울기 사용, dying ReLU 문제 해결을 통해 ReLU보다 성능이 좋음
그림 4. 활성화 함수 그래프
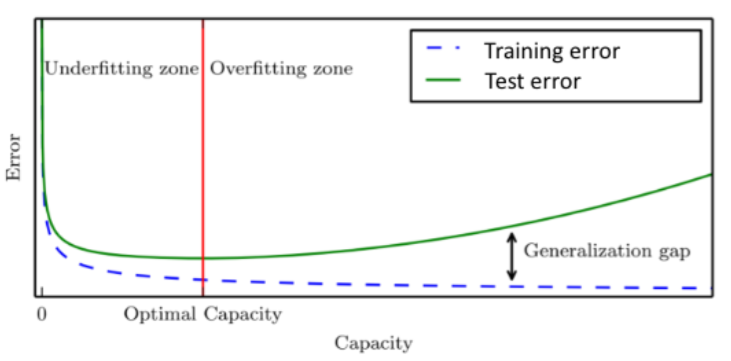
2-3. 정규화
모델은 학습 데이터를 통해 훈련을 하기 때문에 일반적인 상황과의 거리가 멀 수 있다. 따라서 정규화를 통해 모델에서 발생하는 training error가 아닌 generalization error를 감소시켜야 한다.
그림 5. Generalization error
정규화는 아래의 과정을 거쳐 진행한다.
Dropout: 신경망의 일부 유닛을 무작위로 선택하여 학습 과정에서 제외, 네트워크가 특정 뉴런에 의존하지 않도록 하여 일반화 성능을 향상시킴, 학습 할 때마다 무작위로 일부 뉴런을 선택하여 학습 참여에 제외하고 테스트 할 때는 모든 뉴런 사용
Data Augmentation: 데이터 증강은 학습 데이터셋을 변형하여 모델이 다양한 상황에서 더 강건하게 학습되도록 하는 기법, 예를 들어 이미지의 경우 회전, 이동, 크기 조정, 반전 등의 변환
선형 회귀는 지도학습의 한 종류로, 독립 변수(X)와 종속 변수(Y) 간의 선형 관계를 모델링하고 예측하는 데 사용한다. 여기서 종속 변수는 예측하려는 변수로 일반적으로 출력값이고, 독립 변수는 종속 변수에 영향을 주는 변수로 입력값이다. 즉, 선형 회귀는 입력값과 출력값 간의 관계를 선으로 정의하고, 선을 통해 다음 입력값에 대한 출력값을 예측하는 것을 말한다.
1-2. 예시
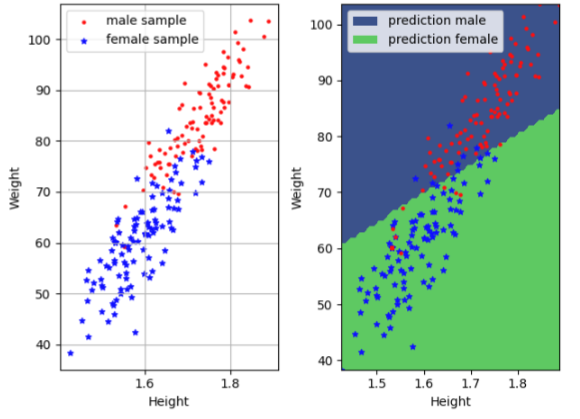
선형 회귀의 예시로 키와 몸무게 쌍의 데이터를 통해 남녀 성별을 예측하는 것이 있다. 아래 그림의 왼쪽 그래프를 보면, 남녀 간의 키 몸무게 쌍의 값이 두 가지 영역으로 구분될 수 있는 것을 볼 수 있다. 선형 회귀는 오른쪽 그래프처럼 입력받았던 키, 몸무게 쌍을 통해 남녀 성별을 예측할 수 있는 선을 긋고, 다음 입력값이 어느 영역에 속하느냐에 따라 해당 값의 성별을 예측하는 것이다.
그림 1. 키와 몸무게 쌍과 성별 간의 선형 회귀 예시
#2 모델
2-1. 수학적 정의
수학적 측면에서 선형 회귀는 아래와 같은 식으로 나타낼 수 있다. 다음 식에서 Y는 예측값, x는 입력값, w는 가중치이다.
그림 2. 선형 회귀 수학적 정의
위의 정의에서는 하나의 가중치가 사용되고 있지만, 실제 모델에서는 여러가지 특성이 고려될 수 있어야 한다. 따라서 여러 가지 특성을 고려하는 특성 함수를 정의하고, 각각의 특성에 대한 가중치를 정의하는 것이 선형 회귀에서는 중요하다. 선형 회귀의 학습은 가중치와 편향을 찾고, 실제값과 예측값의 오차를 가장 적게하는 것을 목표로 한다.
2-2. 손실 함수 (Loss function)
손실 함수는 예측값과 실제값의 오차를 나타내는 함수이다. 손실 함수의 정의는 예측값에 실제값을 뺀 후 제곱하여 입력값의 개수만큼을 나눈 것이다. 제곱을 하는 이유는 오차를 항상 양수만 사용하여 절대값이 모델로부터 얼마나 벗어나는 지를 비교하고, 손실 함수를 통해 최적의 가중치를 찾을 때 미분을 사용하여 기울기가 0인 점을 찾기 위해서이다. 이에 따른 손실 함수의 수학적 정의는 아래와 같다.
그림 3. 손실함수의 수학적 정의그림 4. 손실 함수 그래프
위의 손실함수의 정의는 모든 오차를 동일하게 취급하는 평균제곱오차(MSE) 방식의 정의이다. 이외에도 오차를 표현하는 함수는 다양한 방식(평균 절대 오차, 평균 제곱근 오차, 평균 제곱 로그 오차, 후버 손실 등)이 있다.
2-3. 최적화 (Opimization)
모델의 오차를 최소화 하기 위해, 가중치에 따른 손실함수를 최솟값을 찾아야 한다.
경사하강법
경사하강법은 함수의 최솟값을 찾는 방법으로 손실함수에서도 최솟값을 찾기 위해 사용되기도 한다. 경사하강법은 초기에 임의의 점을 선택하고, 편미분을 통해 점의 기울기를 찾는다. 이후 기울기의 반대 방향으로 이동하며 최솟값을 찾는다. 점을 이동할 때는 학습률이라는 하이퍼 파라미터를 이용하여 얼마나 큰 단계로 이동할 지 선택할 수 있으며, 충분한 반복을 통해 최적점에 수렴하게 된다. 하지만 학습률이 너무 크거나 작은 경우 수렴하지 못 하기 때문에 학습률을 잘 설정하여야 한다.
그림 5. 경사하강법 수학적 정의그림 6. 경사하강법 그래프
경사하강법은 크게 세 가지 종류가 있으며 다음과 같다.
(Full) batch gradient descent: 전체 데이터에서 기울기를 계산
Mini-batch gradient descent: 데이터의 서브셋에서 기울기를 계산
Stochastic gradient descent: 하나의 샘플에서 기울기를 계산
학습률
앞서 말한 것처럼 학습률을 설정하는 것은 중요하다. 이를 최적화 하는 학습률 조절 알고리즘들은 다음과 같다.
Adagrad (Adaptive Gradient Algorithm): 과거의 그래디언트를 보존하여 학습률을 조절하는 방식, 학습이 진행됨에 따라 이전 그래디언트의 제곱값을 누적하여 학습률을 조정, 이는 각각의 매개변수에 대해 개별적으로 학습률을 조절하여 자주 등장하지 않는 특성에 대해서는 큰 학습률을 적용하고 자주 등장하는 특성에 대해서는 작은 학습률을 적용하는 효과를 가져옴, 그러나 학습이 진행됨에 따라 누적된 제곱 그래디언트가 너무 커지면 학습률이 매우 작아져서 학습이 멈출 수 있음
RMSprop (Root Mean Square Propagation): Adagrad의 한계를 극복하기 위해 제안된 방법, 누적된 제곱 그래디언트의 평균을 사용하여 학습률을 조절, 이전 그래디언트의 제곱값을 지수 이동 평균을 사용하여 계산하여 학습률을 조정, 이를 통해 Adagrad보다는 더 안정적으로 학습
Adam (Adaptive Moment Estimation): 모멘텀 최적화와 RMSprop을 결합한 방법으로, 각 매개변수마다 학습률을 조정, 지수 이동 평균을 사용하여 그래디언트와 그래디언트의 제곱값을 추정하고 이를 사용하여 매개변수를 업데이트, 모멘텀 방법을 통해 관성을 고려하여 이전 그래디언트의 영향을 조절, Adam은 다양한 문제에서 효과적으로 작동하며 많은 딥 러닝 모델에서 기본 최적화 알고리즘으로 사용
Authors: Henry N.Schuh, Henry M.Levy, Arvind Krishnamurthy, Luigi Rizzo,Brent E.stephens,David Culler, Samira Khan
Groups: Google, Uni of Washington, Uni of Virginia, Uni of Utah
Keywords: PCIe, NIC, Interface, Cache-Coherent
#1 Motivations
1-1. PCIe overheads
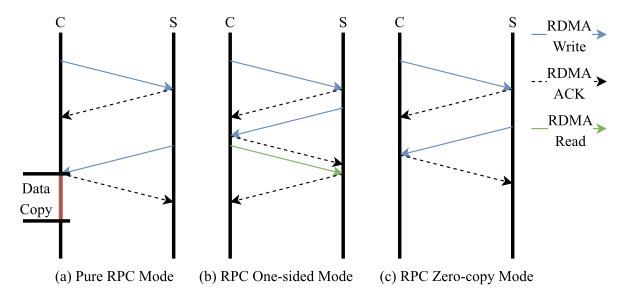
호스트는 디바이스의 메모리에 직접적으로 read/write 연산을 수행하기 위해 일반적으로 MMIO를 이용한다. MMIO를 이용할 때에는 보통 uncacheable(UC) 또는 write-combining(WC) 메모리 타입을 이용하여 데이터를 전달한다. UC와 WC 메모리는 모두 캐싱이 불가능하기 때문에 MMIO read/write 연산은 PCIe 트랜잭션을 기다려야 하고, 이는 높은 지연시간을 발생시킨다. 또한 MMIO load 같은 연산에서 발생하는 PCIe 폴링 CPU 연산은 오버헤드가 크다.
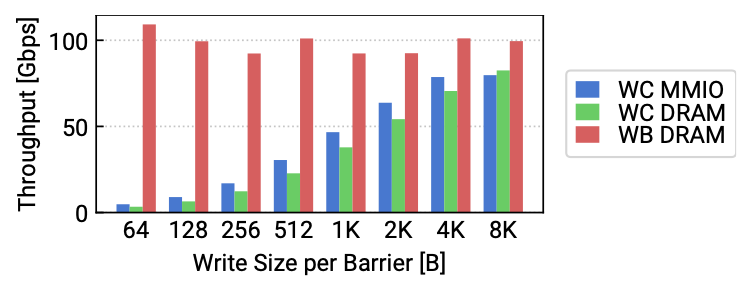
단방향 소통이 가능한 MMIO store는 연속된 데이터에 대한 요청을 하나씩 처리하기 때문에 처리량 저하가 너무 크다. 이는 WC 사이즈에 따른 처리량 변화를 통해 확인할 수 있다. 이를 확인하기 위해 논문에서는 WC MMIO와 WC-mapped local DRAM, write-back DRAM의 성능을 비교하였다. WC data path는 4KB 이상의 크기에서 캐싱과 유사한 처리량을 보여주었다.
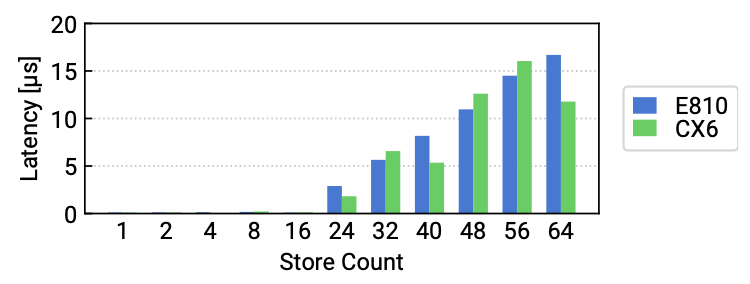
지연시간 측면에서도 WC의 제한된 사이즈에 의한 오버헤드가 발생한다. WC가 가득 찬 상황에서 새로운 store 연산을 요청하려면, 요청은 WC의 플러시를 기다려야 한다. WC 플러시 오버헤드를 측정하기 위해 논문에서는 n개의 store에 연산에 대한 latency를 측정하였다. 실험의 결과를 보면 24개의 store를 수행하기 전까지는 지연 시간이 0과 가깝지만, 그 이후부터는 연산이 많아지는 만큼 오버헤드가 늘어난다.
그림 1. MMIO Performance
정리하면 PCIe 통신의 오버헤드는 다음과 같다.
PCIe는 cache-coherent interconnect가 아니기 때문에 일관성을 유지하기 위해 PCIe 트랜잭션이 필요하다.
PCIe 연산의 높은 지연시간 때문에 연산 횟수를 줄이는 것이 저지연 패킷 통신에 중요하다.
PCIe를 통해 데이터와 메타데이터를 전달하는 것은 CPU의 관점에서 오버헤드가 크다.
1-2. PCIe NIC Interface Design
PCIe 오버헤드로 인해 PCIe 인터페이스는 아래와 같은 설계를 통해 지연 시간을 희생하면서 CPU 효율성과 처리량을 우선시한다.
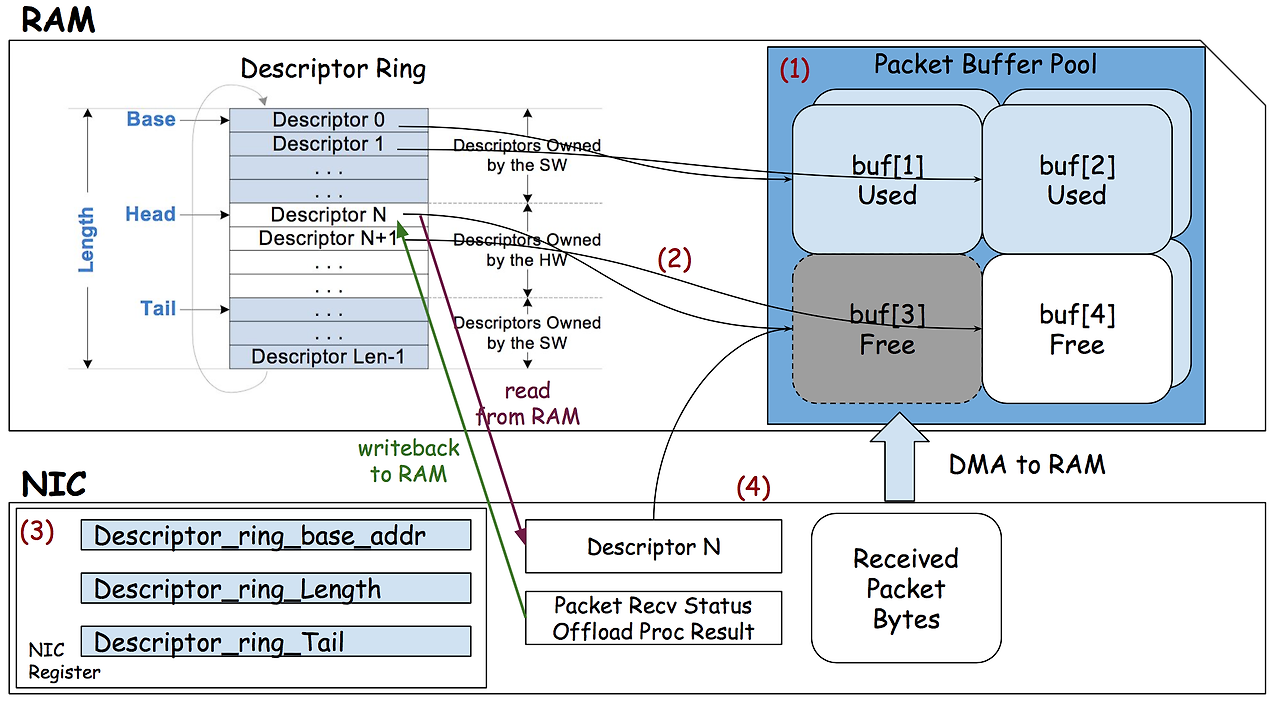
CPU 오버헤드를 줄이기 위해 패킷 버퍼와 디스크립터를 로컬 메모리에 유지하고 패킷 송수신은 PCIe를 통해 NIC으로 전달
디스크립터를 배칭을 통해 전달하여 지연시간은 높지만 CPU 효율성을 증가
동기화가 보장되지 않는 PCIe 버퍼 동기화를 호스트가 관리
#2 CC-NIC
2-1. Coherent interconnects
UPI나 CXL 같은 coherent interconnect들은 CPU의 메모리 데이터패스와 긴밀하게 융합되어 있는데, 이들은 주로 DRAM와 캐시들의 접근을 다룬다. 캐시 일관성 프로토콜은 메모리에 접근할 때 캐시 라인을 캐시에 전송하고, 캐시 간의 공유 상태를 관리하는 역할을 한다. 프로토콜은 writer가 write 전 캐시에 대한 제어를 얻어 원격 캐시에 대한 복사를 방지한다. 그리고 여러 캐시에 reader의 접근을 공유하고 캐시 라인은 캐시 간에 공유된다.
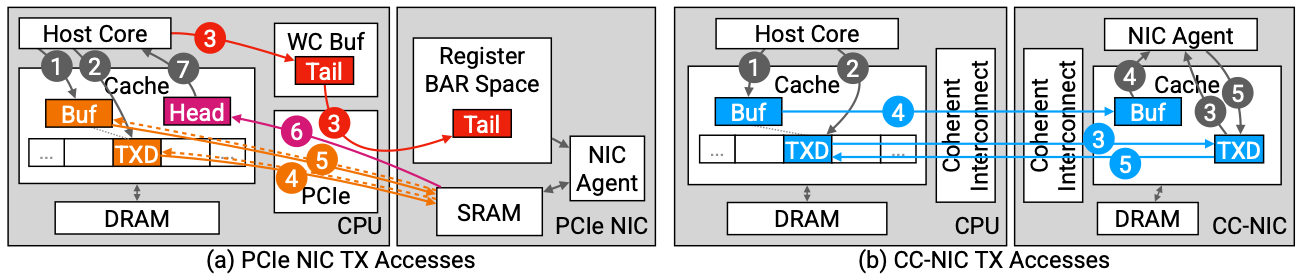
캐시 일관성 추상화는 PCIe read/write 인터페이스의 제한과 상관없이 새로운 형태의 시그널과 데이터 구조를 공유한다. 프로토콜은 PCIe MMIO와 다르게 메모리 데이터 패스와 캐시 계층을 합치고, MMIO와 DMA의 트레이드오프를 피하는 인터페이스를 제공한다. 하지만 캐시간의데이터전송은여러가지요소에의해영향을받는다. 이러한요소는데이터전송에소요되는시간뿐만아니라메모리컨트롤러와의통신, 프로토콜에서사용되는부가적인메타데이터의처리등이 있다. 또한, 캐시라인의상태와전반적인캐싱동작을조작하는데는제한적인수단이있으며, 이러한제한적인조작은캐시일관성및전송성능에영향을줄수있다.
그림 2. Comparison of TX path
2-2. Metadata structures
How can we take advantage of cache coherence to reduce software overhead?
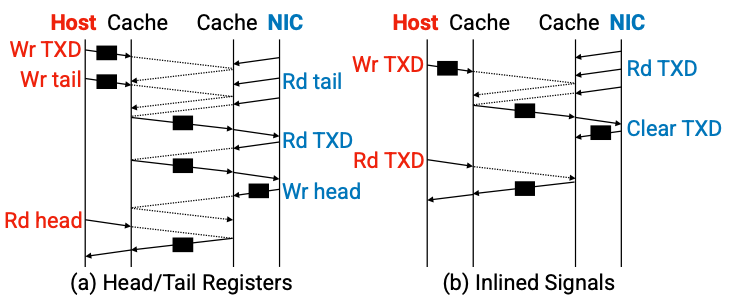
캐시 일관성 프로토콜은 기존 하드웨어 메커니즘과 다르게 캐시의 상태를 바꿈으로써 시그널을 전달할 수 있다. 이것은 헤드테일 인덱스 레지스터를 이용하는 오버헤드를 제거할 수 있다. 따라서 CC-NIC은 디스크립터 내에 inlined signal 플래그를 둠으로써 신호를 전달한다. 이는 소켓 캐시 간의 캐시 라인을 전송하는 지연 시간을 제거한다.
그림 3. Signaling communication
What is the ideal data path for metadata transfer?
메모리 각 계층에서 캐시 일관성 프로토콜을 사용하였을 때의 지연시간을 측정한 결과는 아래 그림과 같다. 로컬 메모리 접근 지연시간에 비해 원격 메모리에 접근하는 지연 시간이 2배 정도 오래 걸리며, homed on local memory가 home on remote memory보다 조금 더 높은 지연시간을 보인다.
그림 4. Local and cross-UPI access latency
CC-NIC은 이러한 특징을 이용하여 TX 디스크립터 링은 host-homed이고, RX 디스크립터 링은 NIC-home로 유지하는 방식으로 metadata structure를 write-home memory에 위치시킨다.
How does memory layout affect metadata?
asdasd
How do we optimize for both latency-sensitive and high-bandwidth regimes?
인라인 시그널을 통해 호스트와 NIC은 디스크립터 링 메모리를 직접적으로 폴링 할 수 있다. 하지만 이는 디스크립터가 64B 캐시라인보다 작기 때문에 64B 캐시라인 단위로 디스크립터를 읽는 오버헤드가 발생한다. 따라서 이를 해결하기 위해 CC-NIC은 16B 디스크립터를 4개씩 캐시 라인으로 구현함으로써 지연시간과 대역폭 오버헤드를 해결하였다.
2-3. Data accesses
How should we write packet data?
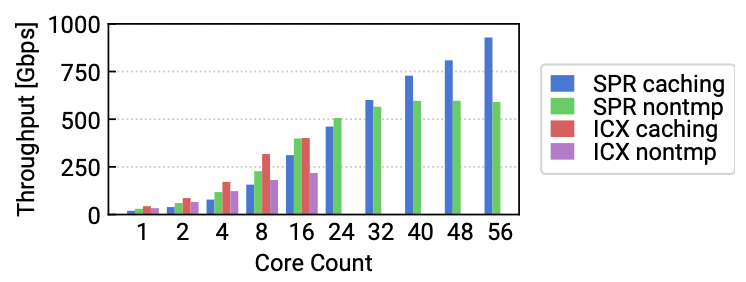
패킷을 캐시에 쓸 때와 DRAM에 쓸 때의 성능을 비교하기 위해 streaming write microbenchmark를 수행하였다. 실험은 패킷을 캐시에 쓴 후 1MB씩 reader가 인라인 시그널을 통해 패킷을 처리하는 것과 DRAM에 쓴 후 1MB씩 처리하였을 때의 처리량을 비교하였다. 아래 그림에서 알 수 있다시피 결과는 캐시에 쓰는 것이 DRAM보다 성능이 좋았기 때문에 CC-NIC에서는 캐시에 패킷 데이터를 쓴다.
그림 5. Stream transfer experiments
How can we minimize coherence protocol overhead for data transfer?
DMA API에서 사용되는 주소 공간은 3가지가 있다. 각각의 주소 공간들은 모두 CPU, 메모리, 디바이스의 관점에서 주소 공간을 정의하여 메모리의 주소를 나타내기 위해 사용한다.
Bus Address Space
디바이스가 메모리에 접근하기 위해 사용하는 주소 공간
MMIO나 DMA를 사용할 때 주로 사용
IOMMU에 의해 메모리 주소에 매핑되거나 오프셋이 직접 매핑되어 사용
Physical Address Space
CPU가 접근하는 메모리의 물리 주소를 나타내는 주소 공간
일반적으로 virtual address space와 매핑되어 사용
Virtual Address Space
CPU가 가상 메모리를 위해 사용하는 주소 공간
kmalloc(), vmalloc()과 같은 인터페이스로 반환되는 void * 형식의 주소
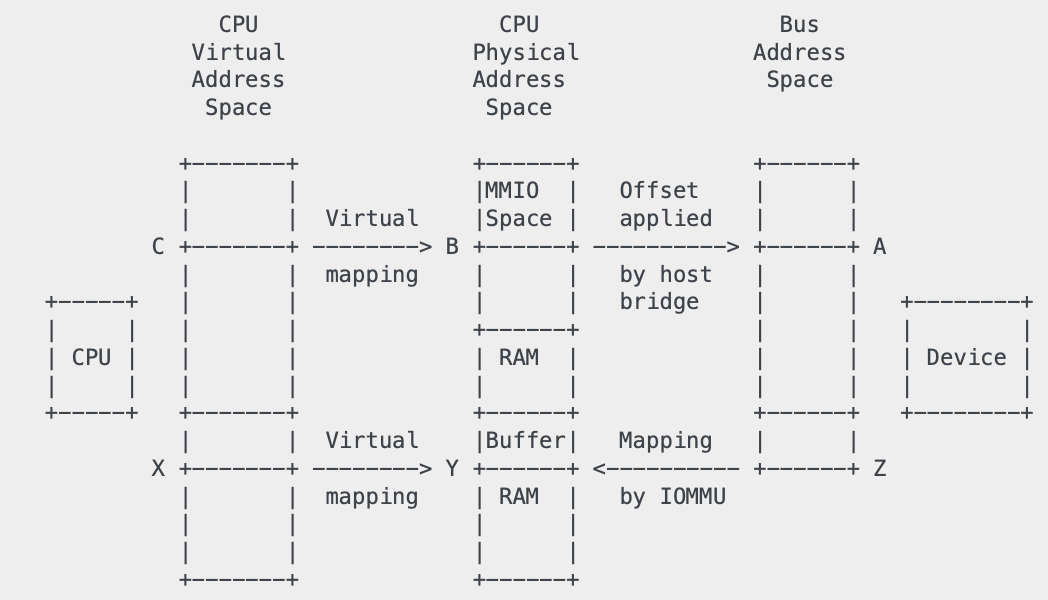
그림 1. Address Mapping 예
각각의 주소 공간이 서로 매핑이 되어야 CPU가 디바이스의 메모리에 접근하고, 디바이스가 메모리에 접근할 수 있게 된다. 주소 공간을 매핑하는 방법은 크게 2가지가 있다. 먼저, PCIe 디바이스가 BAR를 가지고 있는 경우 커널은 BAR의 주소(A)를 읽어 호스트 브릿지를 통해 물리 메모리 주소(B)로 변환한다. 물리 메모리 주소(B)는 /proc/iomem 파일에 구조체 형식으로 정의되어 저장된다. 드라이버가 디바이스에게 요청할 때는 ioremap() 함수를 통해 물리 메모리 주소 (B)를 가상 메모리 주소(C)로 치환하여 사용한다.
만약 디바이스가 DMA를 지원하는 경우, 드라이버는 먼저 kmalloc()과 같은 함수를 통해 물리 메모리에 버퍼를 할당(Y)하고 가상 주소를 매핑하여 해당 주소(X)를 반환한다. 그리고 버스 주소 공간과 매핑하기 위해 IOMMU를 통해 버스 주소(Z)를 물리 메모리 주소(Y)로 변환한다. 예를 들어 dma_map_single()과 같은 함수로 가상 주소(X)를 IOMMU 매핑을 통해 버스 주소(Z)와 매핑 후 반환할 수 있다.
DMA API는 microprocessor와 독립적으로 동작하기 때문에 DMA API를 사용할 때는 특정 버스의 DMA API보다 일반 DMA API를 사용하기를 커널 공식 문서에서는 권장한다.
#2 DMA'able memory
일반적인 페이지 할당자(__get_free_page*(), kmalloc(), kmem_cache_alloc())을 이용하여 반환받은 가상 주소는 DMA 메모리 영역으로 사용할 수 있다. 하지만 vmalloc()으로 메모리를 할당한 경우, 가상 주소는 연속적이나 물리 메모리 주소가 연속적이지 않을 수 있기 때문에 이를 맞춰주어야 하는 번거로움이 있다. 그리고 이런 메모리 영역은 DMA와 물리적으로 작동할 수 있더라도, I/O 버퍼가 캐시 라인으로 정렬되어 있음을 보장하여야 한다. 그렇지 않으면 CPU와 DMA-incoherent 캐시의 캐시라인 공유 문제가 발생한다. (CPU는 한 word를 기준으로 I/O가 이루어지고 DMA는 하나의 캐시라인을 기준으로 I/O가 이루어지기 때문에 다른 캐시 라인이 덮어쓰일 수 있다.)
#3 DMA address capacity
디바이스의 관점에서 DMA는 버스 주소 공간을 사용하지만 이 주소는 시스템의 주소 체계에 의해 제한될 수 있다. 예를 들어, 디바이스가 64비트 체계를 사용하더라도, 32비트 체계의 시스템을 사용함으로써 주소 공간의 크기가 32비트로 제한될 수 있다. 따라서 아래 함수를 통해 DMA mask를 설정하여 DMA 주소 체계를 매핑할 필요가 있다.
int dma_set_mask_and_coherent(struct device *dev, u64 mask); // set up streaming mask & coherent mask int dma_set_mask(struct device *dev, u64 mask); // set up streaming mask int dma_set_coherent_mask(struct device *dev, u64 mask); // set up coherent mask
#4 DMA direction
DMA 방향은 아래와 같으며, 방향을 알면 성능 최적화를 위해 최대한 맞춰 설정하기를 권장한다. 또한, 특정 플랫폼에서는 page protection와 같은 write 권한 이슈가 있기 때문에 방향을 구체적으로 설정하기를 권장한다.
DMA_BIDIRECTIONAL // memory <-> device DMA_TO_DEVICE // memory -> device DMA_FROM_DEVICE // memory <- device DMA_NONE // used for debugging
DMA_NONE의 경우 디버깅의 용도로 많이 사용하며, 구체적인 DMA 방향을 모를 때 사용하면 어느 방향으로 DMA가 이루어지는 지 알 수 있도록 도와준다.
MMIO는 컴퓨터 구조에서 디바이스와 CPU 간의 통신 최적화 과정에서 개발되었다. MMIO를 이해하기 위해서는 MMIO 이전의 컴퓨터 구조를 살펴볼 필요가 있다. 이전의 컴퓨터 구조에서는 여러 디바이스가 같이 사용하는 공통 버스와 각각의 디바이스를 위한 제어 버스가 존재하였다. 공통 버스는 CPU와 디바이스 사이의 주소 공간을 전달하는 주소 버스와 데이터를 전달하는 데이터 버스로 이루어져 있고, 제어 버스는 각 디바이스에게 I/O 명령어를 보내기 위한 제어 라인 버스가 있다.
그림 1. Isolated I/O Bus Overview
하지만 이는 디바이스가 점점 많아지는 현대의 컴퓨터 구조에서는 아래와 같은 이유들로 비효율적이다.
각 디바이스 메모리를 주소 공간에 매핑하기 위한 별개의 주소 공간 -> 많은 디바이스 주소 공간들이 모두 메모리에 할당
각 디바이스 메모리 주소 공간을 사용하기 위한 별개의 명령어들 -> 여러 개의 CPU 명령어, 구현하기에 복잡함, 느림
버스의 수가 늘어나기 때문에 하드웨어 구조가 복잡해짐
#2 MMIO
위의 단점들을 해결하는 방법으로 MMIO가 등장하였다. MMIO의 기본 원리는 디바이스 메모리를 메모리 주소 공간에 매핑하는 것이다. 이를 통해 CPU가 각 디바이스들의 주소 공간을 이용하기 위해 여러 개의 명령어를 사용하던 것과 달리 메모리 주소 공간만 사용할 수 있게 되었으며, 하나의 공통 제어 버스를 사용하여 여러 디바이스에 I/O 명령을 할 수 있게 되었다.
그림 2. MMIO Bus Overview
이런 MMIO는 다음과 같은 장점들을 갖는다.
CPU가 디바이스에 메모리와 같은 속도로 접근할 수 있게 됨 -> 빨라짐
메모리와 디바이스 주소 공간에 접근하는 명령어가 하나로 단순화 됨 -> 구현이 쉬워짐
메모리 주소 공간 안에 여러 개의 디바이스 메모리 주소 공간을 매핑 -> 효율적인 메모리 사용
그림 3. Address space overview
하지만 MMIO가 갖고 있는 단점들도 있다.
메모리 주소 공간에 여러 개의 디바이스 메모리 주소 공간을 매핑하기 때문에 디바이스를 위한 주소 공간이 제한됨
디바이스의 처리 속도가 느리기 때문에 제어 버스에 병목점이 발생할 수 있음 -> 메모리 접근이 느려질 수 있음
#3 MMIO operation
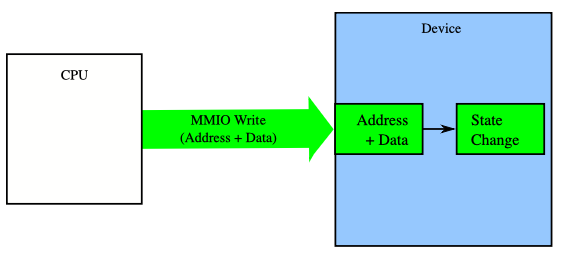
MMIO store는 단방향 소통으로 CPU가 메모리 주소 공간에 매핑된 디바이스 메모리의 주소를 통해 CPU 캐시의 데이터를 전송한다. 반면에 load는 양방향 소통으로 CPU가 디바이스 메모리 주소를 디바이스에 요청하면, 디바이스가 CPU 캐시에 데이터를 전송한다. 따라서 store는 호스트의 관점에서 명령을 전달하면 요청이 완료되지만, load는 데이터를 전달받기까지 데이터를 폴링하고 있어야 한다.
그림 4. MMIO operation
위와 같은 상황에서 store 연산과 load 연산이 동시에 발생한다고 가정하면, 일관성과 동시성 문제에 있어서 순서를 보장하는 것이 매우 중요하다. 리눅스의 경우 커널 단위에서 아토믹 연산과 lock을 통해 순서 보장을 지원한다. 하지만 디바이스의 메모리는 이런 순서 보장에 취약하기 때문에 PCIe 상에 inflight 되는 요청은 하나만 가능하다. 따라서 store 연산은 연속된 요청이 들어와도 하나씩만 수행 가능하기 때문에 throughput이 매우 떨어지게 된다. 이를 해결하기 위해 커널에서는 Write-Combining Buffer(WC)를 이용하여 store 연산을 batching을 통해 throughput을 향상한다. MMIO는 일반적으로 작은 단위의 데이터 전달을 수행하기 때문에 WC의 사이즈는 64B cache-alined이며, 연산 간의 순서 및 버퍼 플러쉬를 보장하기 위해 sfence와 같은 알고리즘과 같이 동작한다.
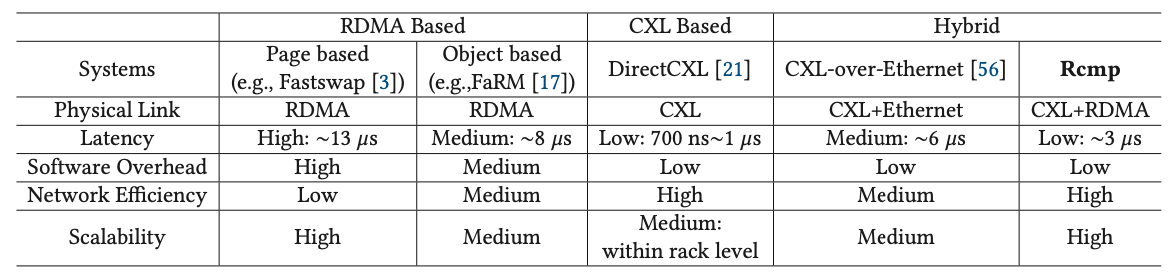
데이터를 관리하는 기법에 따라 RDMA 기반의 메모리 분리는 두 종류로 나뉜다. 페이지 기반의 기법에서는 가상 메모리 메커니즘을 이용하여 페이지 폴트가 발생하였을 때 로컬 메모리와 원격 메모리 페이지를 스와핑함으로써 원격 메모리 상의 페이지를 로컬 메모리로 캐싱한다. 이 방법은 응용의 수정 없이 적용이 가능하다는 장점이 있다. 오브젝트 기반의 기법에서는 메모리 관리를 조금 더 세밀한 단위(객체)로 하며 객체의 시맨틱을 이용하여 컴퓨팅 리소스를 최적화 한다. 하지만 RDMA 기법은 다음과 같은 단점들이 있다.
High latency: 로컬 메모리와 비교하여 20배 이상 느린 지연시간을 제공한다.
High overhead: 페이지 기반서는 페이지 폴트 오버헤드를 동반하고, 오브젝트 기반에서는 코드 수정이 필요하다는 단점이 있다.
1-2. CXL-based memory disaggregation
CXL 기반의 메모리 분리는 캐시 일관성을 보장하는 공유 메모리 풀을 제공하며, 캐시 라인 접근이 가능하게 한다. 이는 응용의 수정이 필요 없으며 낮은 지연시간과 좋은 확장성을 보인다. 그러나 CXL 기반의 메모리 분리는 다음과 같은 단점을 가진다.
Physical distance limitation: CXL 디바이스는 PCIe를 기반으로 하기 때문에 랙 레벨에서의 결합으로 제한되며, 이는 대규모 데이터센터에 바로 적용되기 어렵다.
1-3. Hybrid memory disaggregation
따라서 논문에서는 CXL의 물리적 한계를 보완하고 RDMA의 높은 지연시산과 오버헤드를 보완하기 위해 RDMA와 CXL 기법을 결합하여 하이브리드로 동작하는 새로운 기법을 제안한다. 로컬 랙에서는 CXL의 장점을 이용하여 낮은 지연시간을 보이며, 서로 다른 랙을 RDMA를 통해 연결하여 확장성을 보장한다.
그림 1. Comparison of Memory Disaggregation Approaches
#2 Design
2-1. Archtiecture
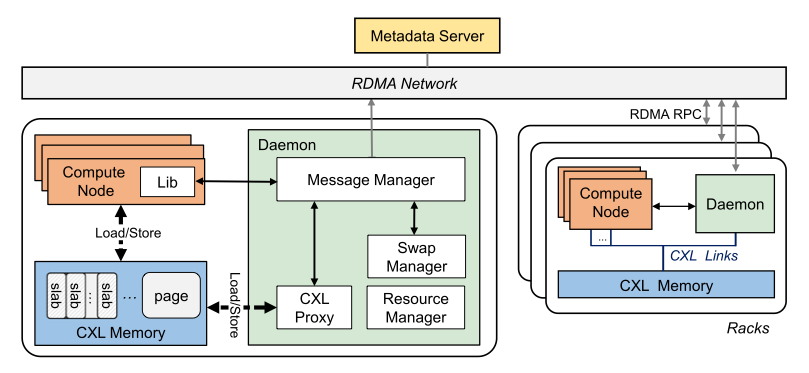
Rcmp 랙은 응용을 위한 여러 개의 컴퓨팅 노드와 CXL, 컴퓨팅 노드의 요청을 처리하기 위한 데몬으로 이루어져 있다. 메모리 노드를 두지 않고 데몬을 통해 요청을 처리하는 구조는 컴퓨팅 노드와 메모리 노드가 분리된 구조에서 발생하는 메모리 일관성을 유지 오버헤드를 없애는 장점이 있다. 그리고 컴퓨팅 노드의 요청에서 발생하는 블로킹을 없애기 동적으로 데몬의 수를 늘릴 수 있다. 랙의 컴퓨팅 노드는 CXL을 통해 메모리 풀을 할당하고, 서로 다른 랙의 컴퓨팅 노드들은 RDMA를 통해 연결된다.
그림 2. Architecture
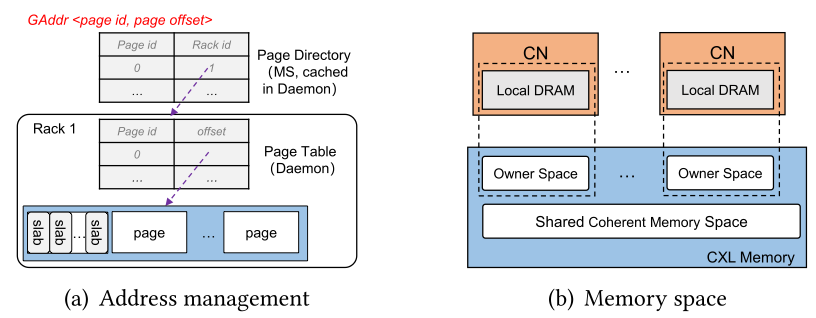
Rcmp는 서로 다른 랙에 존재하는 메모리들을 관리하기 위해 전역 메모리 주소를 사용하며, Metadata Server(MS)를 통해 전역 주소 할당 및 메타데이터 관리를 수행한다.MS는 페이지 단위로 메모리를 할당하며, 전역 주소는 페이지의 id와 CXL 메모리의 페이지 오프셋으로 이루어져 있다. Rcmp는 2개의 해시 테이블을 이용하여 주소 매핑을 관리한다. MS의 page directory는 페이지 id와 랙 id의 매핑을 관리하고, 데몬의 page table은 페이지 id와 페이지 오프셋의 매핑을 관리한다. 메모리 공간은 크게 3가지로 CXL 메모리와 컴퓨팅 노드의 로컬 메모리, 데몬으로 다음과 같은 역할을 한다.
CN: Local page hotness와 local page table 메타데이터를 캐싱
Daemon: Local page table과 원격 메모리의 hotness를 저장, MS의 page directory와 remote page table을 캐싱
CXL: 큰 캐시 일관성 보장 공유 메모리 공간과 컴퓨팅 노드에게 제공되는 메모리 공간
그림 3. Global memory and ddress management
2-2. Workflow
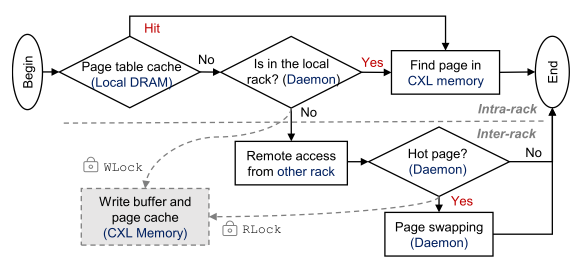
컴퓨팅 노드의 응용이 메모리 풀에 접근하는 것은 다음의 플로우를 따른다.
페이지가 로컬 메모리의 page table에서 발견된다면, load/store 명령어를 통해 CXL 메모리 페이지에 직접 접근
로컬 메모리에서 페이지를 찾지 못 하면, MS의 page directory를 참조하여 페이지가 존재하는 랙을 조회
페이지가 로컬 랙에 존재하면, 로컬 데몬의 page table을 통해 해당 페이지의 오프셋을 얻은 후 CXL 메모리 노드에 접근
페이지가 원격 랙에 존재하면, 원격 데몬에게 요청하여 원격 page table을 통해 해당 페이지의 오프셋을 얻어 RDMA를 통해 CXL 메모리 페이지에 접근 (이때 접근하는 페이지가 hot page인 경우, 스왑 메커니즘을 트리거)
그림 4. Workflow
#3 Rcmp
데몬은 랙의 중앙화된 관리 노드로 CXL 및 RDMA 요청 뿐만 아니라 페이지 스와핑, 슬랩 할당 관리, CXL 메모리를 관리하는 역할을 한다. 데몬은 각 랙에 하나 이상 실행되며 컴퓨팅 노드와 같이 취급된다. 또한 Rcmp의 모든 컴포넌트는 user-level에서 구현되어 컨텍스트 스위치 오버헤드가 없다.
3-1. Intra-rack communication
로컬 랙과 원격 랙에 접근하는 지연 시간의 차이가 커, 블로킹으로 인한 성능 하락을 초래할 수 있다. 이를 해결하기 위해 Rcmp는 각각의 상황에 맞추어 두 가지 링버퍼를 사용한다. 로컬 랙의 접근을 관리하기 위한 링버퍼는 CXL에 접근하는 지연 시간은 매우 짧아 블로킹이 발생하지 않기 때문에 일반적인 링버퍼를 사용한다. 따라서 컴퓨팅 노드의 모든 스레드가 공유하는 하나의 링버퍼를 유지한다.
원격 랙에 접근하기 위한 링 버퍼는 동시성 보장을 위해 두 개의 링버퍼로 이루어져 있다. 첫 번째 링버퍼는 폴링을 위한 링버퍼로 메시지 메타데이터와 메시지 데이터를 보관하는 두 번째 링버퍼를 가리키는 포인터를 저장한다. 폴링 버퍼의 데이터는 고정된 크기의 데이터 규격을 가지며, 데이터 버퍼의 요청이 하나 완료되면 하나의 폴링 버퍼 요청을 추가할 수 있다. 그리고 데몬은 메시지를 처리하기 위해 폴링 버퍼를 폴링 한다. 폴링 버퍼는 lock-free KFIFO 큐를 이용하여 구현하였으며, 데이터 버퍼는 일반적인 링버퍼를 통해 구현하였다.
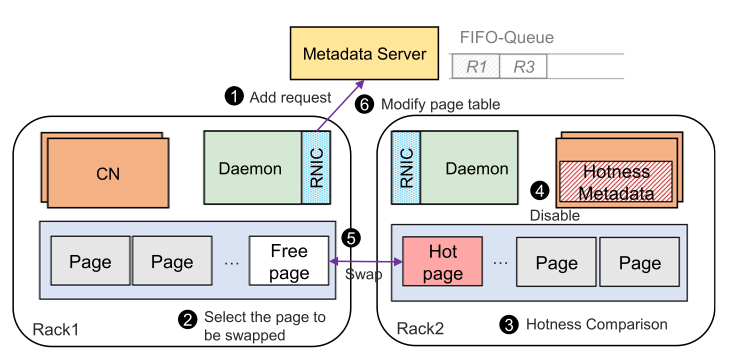
3-2. Hot-page identification and Swapping
Rcmp는 원격 랙 접근 오버헤드를 줄이기 위해, hot page를 로컬에 위치시키려 한다.
Hot-page identification
Rcmp는 read/write 연산의 횟수, last time 세 가지 팩터로 hotness를 측정한다. 먼저 페이지에 접근할 때Δt를 측정하는데, 이는 현재 시간으로부터 마지막으로 read 연산을 수행한 시간을 뺀 것이다. 만약Δt가 valid lifetime threshold T를 넘어가면, 해당 페이지에 대한 hotness는 만료되고 현재 read/write 연산의 횟수가 0으로 초기화된다. 페이지의 hotness는 아래의 공식을 통해 계산한다. hotness가 threshold H를 넘어가면 페이지가 hot하다고 판단하며, (Curr/Curw)가 threshold Rrw를 넘어가면 read hot이라고 판단한다.
α × (Curr + Curw ) + 1
α = e−λΔt, where λ is a decay constant
Hot-page Swapping and Caching
Rcmp는 기존 페이지 기반의 메커니즘이 페이지 폴트를 이용하여 스왑 매커니즘을 수행한 것과 다르게 user-level swap mechanism을 사용한다. Rcmp의 hot 페이지 스왑 알고리즘을 아래의 절차를 따른다.