A Cache-Coherent Interface to the NIC
Authors: Henry N.Schuh, Henry M.Levy, Arvind Krishnamurthy, Luigi Rizzo, Brent E.stephens, David Culler, Samira Khan
Groups: Google, Uni of Washington, Uni of Virginia, Uni of Utah
Keywords: PCIe, NIC, Interface, Cache-Coherent
#1 Motivations
1-1. PCIe overheads
호스트는 디바이스의 메모리에 직접적으로 read/write 연산을 수행하기 위해 일반적으로 MMIO를 이용한다. MMIO를 이용할 때에는 보통 uncacheable(UC) 또는 write-combining(WC) 메모리 타입을 이용하여 데이터를 전달한다. UC와 WC 메모리는 모두 캐싱이 불가능하기 때문에 MMIO read/write 연산은 PCIe 트랜잭션을 기다려야 하고, 이는 높은 지연시간을 발생시킨다. 또한 MMIO load 같은 연산에서 발생하는 PCIe 폴링 CPU 연산은 오버헤드가 크다.
단방향 소통이 가능한 MMIO store는 연속된 데이터에 대한 요청을 하나씩 처리하기 때문에 처리량 저하가 너무 크다. 이는 WC 사이즈에 따른 처리량 변화를 통해 확인할 수 있다. 이를 확인하기 위해 논문에서는 WC MMIO와 WC-mapped local DRAM, write-back DRAM의 성능을 비교하였다. WC data path는 4KB 이상의 크기에서 캐싱과 유사한 처리량을 보여주었다.
지연시간 측면에서도 WC의 제한된 사이즈에 의한 오버헤드가 발생한다. WC가 가득 찬 상황에서 새로운 store 연산을 요청하려면, 요청은 WC의 플러시를 기다려야 한다. WC 플러시 오버헤드를 측정하기 위해 논문에서는 n개의 store에 연산에 대한 latency를 측정하였다. 실험의 결과를 보면 24개의 store를 수행하기 전까지는 지연 시간이 0과 가깝지만, 그 이후부터는 연산이 많아지는 만큼 오버헤드가 늘어난다.
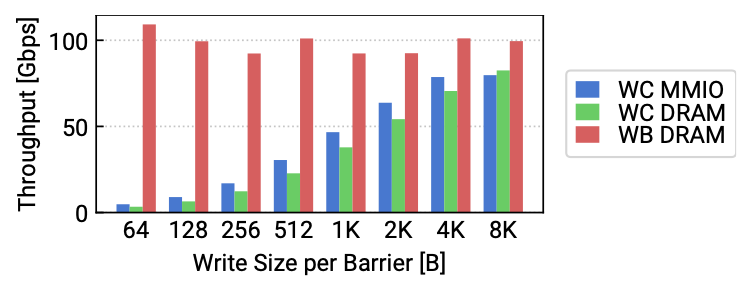
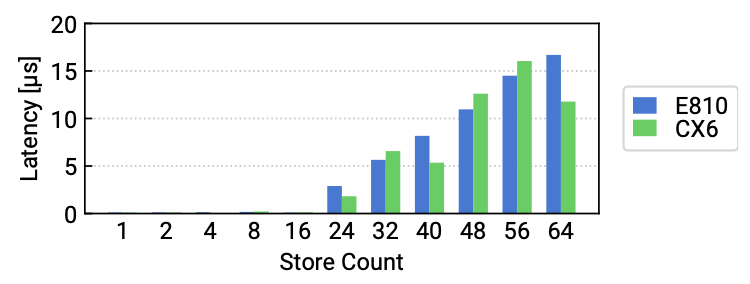
정리하면 PCIe 통신의 오버헤드는 다음과 같다.
- PCIe는 cache-coherent interconnect가 아니기 때문에 일관성을 유지하기 위해 PCIe 트랜잭션이 필요하다.
- PCIe 연산의 높은 지연시간 때문에 연산 횟수를 줄이는 것이 저지연 패킷 통신에 중요하다.
- PCIe를 통해 데이터와 메타데이터를 전달하는 것은 CPU의 관점에서 오버헤드가 크다.
1-2. PCIe NIC Interface Design
PCIe 오버헤드로 인해 PCIe 인터페이스는 아래와 같은 설계를 통해 지연 시간을 희생하면서 CPU 효율성과 처리량을 우선시한다.
- CPU 오버헤드를 줄이기 위해 패킷 버퍼와 디스크립터를 로컬 메모리에 유지하고 패킷 송수신은 PCIe를 통해 NIC으로 전달
- 디스크립터를 배칭을 통해 전달하여 지연시간은 높지만 CPU 효율성을 증가
- 동기화가 보장되지 않는 PCIe 버퍼 동기화를 호스트가 관리
#2 CC-NIC
2-1. Coherent interconnects
UPI나 CXL 같은 coherent interconnect들은 CPU의 메모리 데이터패스와 긴밀하게 융합되어 있는데, 이들은 주로 DRAM와 캐시들의 접근을 다룬다. 캐시 일관성 프로토콜은 메모리에 접근할 때 캐시 라인을 캐시에 전송하고, 캐시 간의 공유 상태를 관리하는 역할을 한다. 프로토콜은 writer가 write 전 캐시에 대한 제어를 얻어 원격 캐시에 대한 복사를 방지한다. 그리고 여러 캐시에 reader의 접근을 공유하고 캐시 라인은 캐시 간에 공유된다.
캐시 일관성 추상화는 PCIe read/write 인터페이스의 제한과 상관없이 새로운 형태의 시그널과 데이터 구조를 공유한다. 프로토콜은 PCIe MMIO와 다르게 메모리 데이터 패스와 캐시 계층을 합치고, MMIO와 DMA의 트레이드오프를 피하는 인터페이스를 제공한다. 하지만 캐시 간의 데이터 전송은 여러 가지 요소에 의해 영향을 받는다. 이러한 요소는 데이터 전송에 소요되는 시간뿐만 아니라 메모리 컨트롤러와의 통신, 프로토콜에서 사용되는 부가적인 메타데이터의 처리 등이 있다. 또한, 캐시 라인의 상태와 전반적인 캐싱 동작을 조작하는 데는 제한적인 수단이 있으며, 이러한 제한적인 조작은 캐시 일관성 및 전송 성능에 영향을 줄 수 있다.
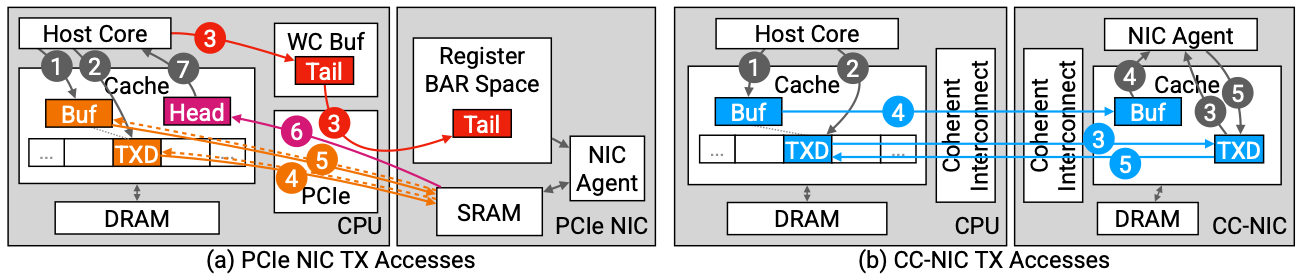
2-2. Metadata structures
- How can we take advantage of cache coherence to reduce software overhead?
캐시 일관성 프로토콜은 기존 하드웨어 메커니즘과 다르게 캐시의 상태를 바꿈으로써 시그널을 전달할 수 있다. 이것은 헤드테일 인덱스 레지스터를 이용하는 오버헤드를 제거할 수 있다. 따라서 CC-NIC은 디스크립터 내에 inlined signal 플래그를 둠으로써 신호를 전달한다. 이는 소켓 캐시 간의 캐시 라인을 전송하는 지연 시간을 제거한다.
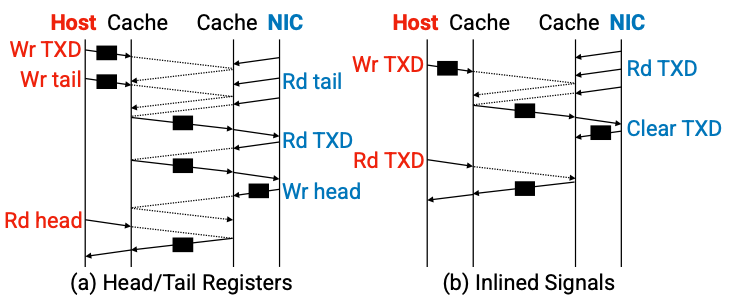
- What is the ideal data path for metadata transfer?
메모리 각 계층에서 캐시 일관성 프로토콜을 사용하였을 때의 지연시간을 측정한 결과는 아래 그림과 같다. 로컬 메모리 접근 지연시간에 비해 원격 메모리에 접근하는 지연 시간이 2배 정도 오래 걸리며, homed on local memory가 home on remote memory보다 조금 더 높은 지연시간을 보인다.

CC-NIC은 이러한 특징을 이용하여 TX 디스크립터 링은 host-homed이고, RX 디스크립터 링은 NIC-home로 유지하는 방식으로 metadata structure를 write-home memory에 위치시킨다.
- How does memory layout affect metadata?
asdasd
- How do we optimize for both latency-sensitive and high-bandwidth regimes?
인라인 시그널을 통해 호스트와 NIC은 디스크립터 링 메모리를 직접적으로 폴링 할 수 있다. 하지만 이는 디스크립터가 64B 캐시라인보다 작기 때문에 64B 캐시라인 단위로 디스크립터를 읽는 오버헤드가 발생한다. 따라서 이를 해결하기 위해 CC-NIC은 16B 디스크립터를 4개씩 캐시 라인으로 구현함으로써 지연시간과 대역폭 오버헤드를 해결하였다.
2-3. Data accesses
- How should we write packet data?
패킷을 캐시에 쓸 때와 DRAM에 쓸 때의 성능을 비교하기 위해 streaming write microbenchmark를 수행하였다. 실험은 패킷을 캐시에 쓴 후 1MB씩 reader가 인라인 시그널을 통해 패킷을 처리하는 것과 DRAM에 쓴 후 1MB씩 처리하였을 때의 처리량을 비교하였다. 아래 그림에서 알 수 있다시피 결과는 캐시에 쓰는 것이 DRAM보다 성능이 좋았기 때문에 CC-NIC에서는 캐시에 패킷 데이터를 쓴다.
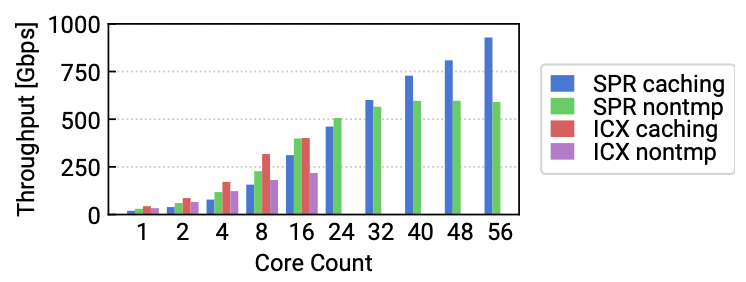
- How can we minimize coherence protocol overhead for data transfer?
asdf
- Where shold data be homed?
asdf
- How can we maximize cache locality for packets?
asdf
2-4. Buffer management
asdasd
내용 추가 예정
'논문 > 네트워크 & 시스템' 카테고리의 다른 글
| Junction - NSDI'24 (0) | 2024.06.20 |
|---|---|
| Nu - NSDI'23 (0) | 2024.04.03 |