Reconfiguring RDMA-based Memory Disggregation via CXL
Authors: Zhonghua Wang, Yixing Guo, Kai Lu, Jiguang Wan, Daohui Wang, Ting Yao, Huatao Wu
Groups: Huazhong University, Huawei Cloud
Keywords: Memory Disaggregation, RDMA, CXL
#1 Motivations
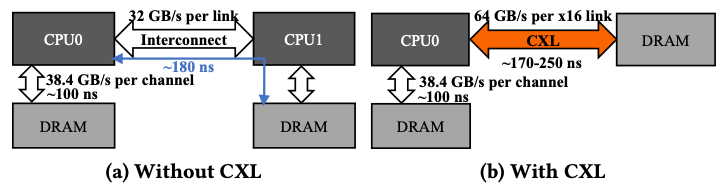
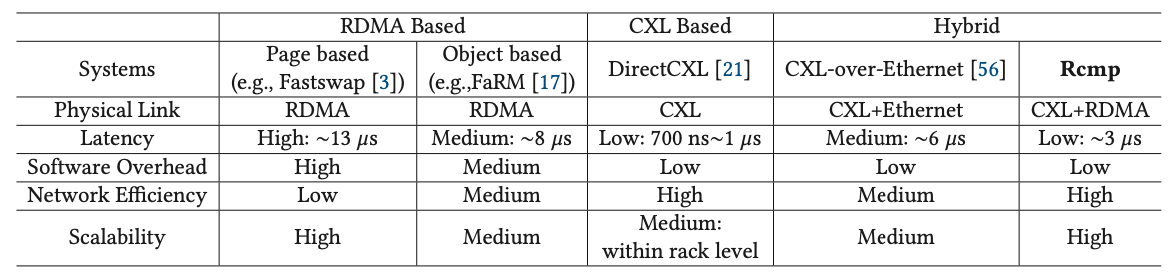
1-1. RDMA-based memory disaggregation
데이터를 관리하는 기법에 따라 RDMA 기반의 메모리 분리는 두 종류로 나뉜다. 페이지 기반의 기법에서는 가상 메모리 메커니즘을 이용하여 페이지 폴트가 발생하였을 때 로컬 메모리와 원격 메모리 페이지를 스와핑함으로써 원격 메모리 상의 페이지를 로컬 메모리로 캐싱한다. 이 방법은 응용의 수정 없이 적용이 가능하다는 장점이 있다. 오브젝트 기반의 기법에서는 메모리 관리를 조금 더 세밀한 단위(객체)로 하며 객체의 시맨틱을 이용하여 컴퓨팅 리소스를 최적화 한다. 하지만 RDMA 기법은 다음과 같은 단점들이 있다.
- High latency: 로컬 메모리와 비교하여 20배 이상 느린 지연시간을 제공한다.
- High overhead: 페이지 기반서는 페이지 폴트 오버헤드를 동반하고, 오브젝트 기반에서는 코드 수정이 필요하다는 단점이 있다.
1-2. CXL-based memory disaggregation
CXL 기반의 메모리 분리는 캐시 일관성을 보장하는 공유 메모리 풀을 제공하며, 캐시 라인 접근이 가능하게 한다. 이는 응용의 수정이 필요 없으며 낮은 지연시간과 좋은 확장성을 보인다. 그러나 CXL 기반의 메모리 분리는 다음과 같은 단점을 가진다.
- Physical distance limitation: CXL 디바이스는 PCIe를 기반으로 하기 때문에 랙 레벨에서의 결합으로 제한되며, 이는 대규모 데이터센터에 바로 적용되기 어렵다.
1-3. Hybrid memory disaggregation
따라서 논문에서는 CXL의 물리적 한계를 보완하고 RDMA의 높은 지연시산과 오버헤드를 보완하기 위해 RDMA와 CXL 기법을 결합하여 하이브리드로 동작하는 새로운 기법을 제안한다. 로컬 랙에서는 CXL의 장점을 이용하여 낮은 지연시간을 보이며, 서로 다른 랙을 RDMA를 통해 연결하여 확장성을 보장한다.
#2 Design
2-1. Archtiecture
Rcmp 랙은 응용을 위한 여러 개의 컴퓨팅 노드와 CXL, 컴퓨팅 노드의 요청을 처리하기 위한 데몬으로 이루어져 있다. 메모리 노드를 두지 않고 데몬을 통해 요청을 처리하는 구조는 컴퓨팅 노드와 메모리 노드가 분리된 구조에서 발생하는 메모리 일관성을 유지 오버헤드를 없애는 장점이 있다. 그리고 컴퓨팅 노드의 요청에서 발생하는 블로킹을 없애기 동적으로 데몬의 수를 늘릴 수 있다. 랙의 컴퓨팅 노드는 CXL을 통해 메모리 풀을 할당하고, 서로 다른 랙의 컴퓨팅 노드들은 RDMA를 통해 연결된다.
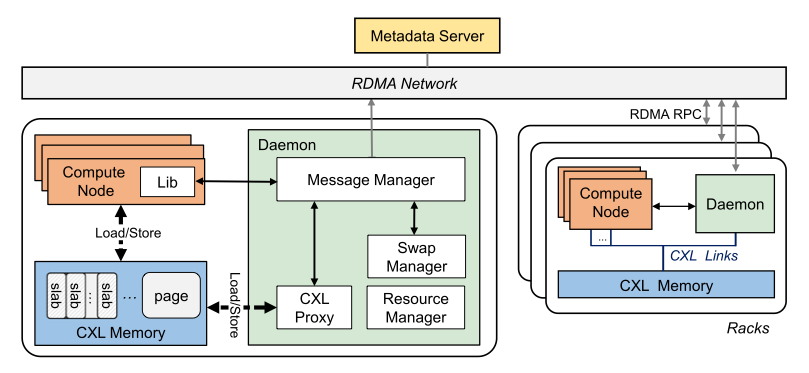
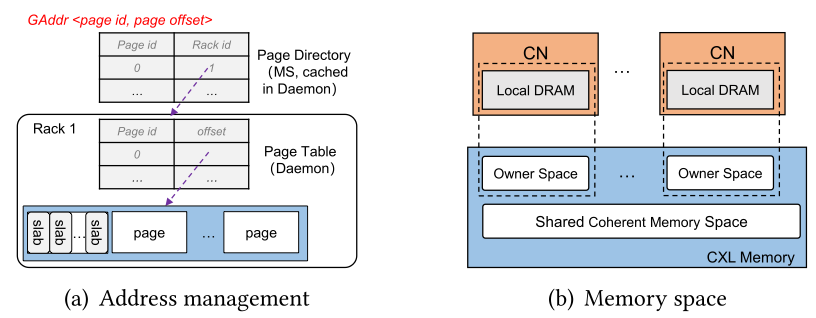
Rcmp는 서로 다른 랙에 존재하는 메모리들을 관리하기 위해 전역 메모리 주소를 사용하며, Metadata Server(MS)를 통해 전역 주소 할당 및 메타데이터 관리를 수행한다. MS는 페이지 단위로 메모리를 할당하며, 전역 주소는 페이지의 id와 CXL 메모리의 페이지 오프셋으로 이루어져 있다. Rcmp는 2개의 해시 테이블을 이용하여 주소 매핑을 관리한다. MS의 page directory는 페이지 id와 랙 id의 매핑을 관리하고, 데몬의 page table은 페이지 id와 페이지 오프셋의 매핑을 관리한다. 메모리 공간은 크게 3가지로 CXL 메모리와 컴퓨팅 노드의 로컬 메모리, 데몬으로 다음과 같은 역할을 한다.
- CN: Local page hotness와 local page table 메타데이터를 캐싱
- Daemon: Local page table과 원격 메모리의 hotness를 저장, MS의 page directory와 remote page table을 캐싱
- CXL: 큰 캐시 일관성 보장 공유 메모리 공간과 컴퓨팅 노드에게 제공되는 메모리 공간
2-2. Workflow
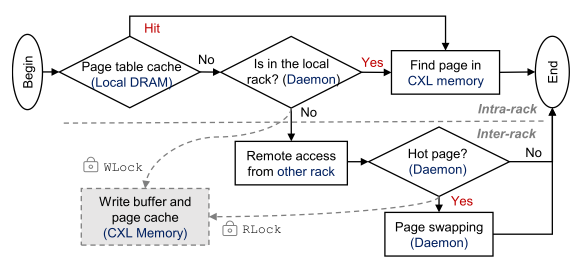
컴퓨팅 노드의 응용이 메모리 풀에 접근하는 것은 다음의 플로우를 따른다.
- 페이지가 로컬 메모리의 page table에서 발견된다면, load/store 명령어를 통해 CXL 메모리 페이지에 직접 접근
- 로컬 메모리에서 페이지를 찾지 못 하면, MS의 page directory를 참조하여 페이지가 존재하는 랙을 조회
- 페이지가 로컬 랙에 존재하면, 로컬 데몬의 page table을 통해 해당 페이지의 오프셋을 얻은 후 CXL 메모리 노드에 접근
- 페이지가 원격 랙에 존재하면, 원격 데몬에게 요청하여 원격 page table을 통해 해당 페이지의 오프셋을 얻어 RDMA를 통해 CXL 메모리 페이지에 접근 (이때 접근하는 페이지가 hot page인 경우, 스왑 메커니즘을 트리거)
#3 Rcmp
데몬은 랙의 중앙화된 관리 노드로 CXL 및 RDMA 요청 뿐만 아니라 페이지 스와핑, 슬랩 할당 관리, CXL 메모리를 관리하는 역할을 한다. 데몬은 각 랙에 하나 이상 실행되며 컴퓨팅 노드와 같이 취급된다. 또한 Rcmp의 모든 컴포넌트는 user-level에서 구현되어 컨텍스트 스위치 오버헤드가 없다.
3-1. Intra-rack communication
로컬 랙과 원격 랙에 접근하는 지연 시간의 차이가 커, 블로킹으로 인한 성능 하락을 초래할 수 있다. 이를 해결하기 위해 Rcmp는 각각의 상황에 맞추어 두 가지 링버퍼를 사용한다. 로컬 랙의 접근을 관리하기 위한 링버퍼는 CXL에 접근하는 지연 시간은 매우 짧아 블로킹이 발생하지 않기 때문에 일반적인 링버퍼를 사용한다. 따라서 컴퓨팅 노드의 모든 스레드가 공유하는 하나의 링버퍼를 유지한다.
원격 랙에 접근하기 위한 링 버퍼는 동시성 보장을 위해 두 개의 링버퍼로 이루어져 있다. 첫 번째 링버퍼는 폴링을 위한 링버퍼로 메시지 메타데이터와 메시지 데이터를 보관하는 두 번째 링버퍼를 가리키는 포인터를 저장한다. 폴링 버퍼의 데이터는 고정된 크기의 데이터 규격을 가지며, 데이터 버퍼의 요청이 하나 완료되면 하나의 폴링 버퍼 요청을 추가할 수 있다. 그리고 데몬은 메시지를 처리하기 위해 폴링 버퍼를 폴링 한다. 폴링 버퍼는 lock-free KFIFO 큐를 이용하여 구현하였으며, 데이터 버퍼는 일반적인 링버퍼를 통해 구현하였다.
3-2. Hot-page identification and Swapping
Rcmp는 원격 랙 접근 오버헤드를 줄이기 위해, hot page를 로컬에 위치시키려 한다.
- Hot-page identification
Rcmp는 read/write 연산의 횟수, last time 세 가지 팩터로 hotness를 측정한다. 먼저 페이지에 접근할 때 Δt를 측정하는데, 이는 현재 시간으로부터 마지막으로 read 연산을 수행한 시간을 뺀 것이다. 만약 Δt가 valid lifetime threshold T를 넘어가면, 해당 페이지에 대한 hotness는 만료되고 현재 read/write 연산의 횟수가 0으로 초기화된다. 페이지의 hotness는 아래의 공식을 통해 계산한다. hotness가 threshold H를 넘어가면 페이지가 hot하다고 판단하며, (Curr/Curw)가 threshold Rrw를 넘어가면 read hot이라고 판단한다.
α × (Curr + Curw ) + 1
α = e−λΔt, where λ is a decay constant
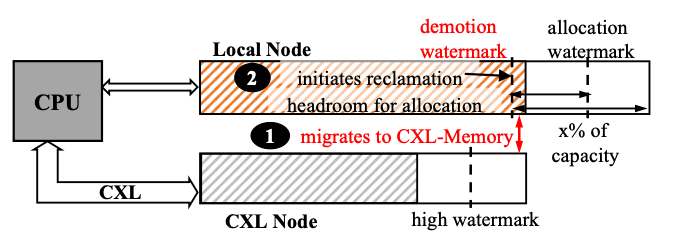
- Hot-page Swapping and Caching
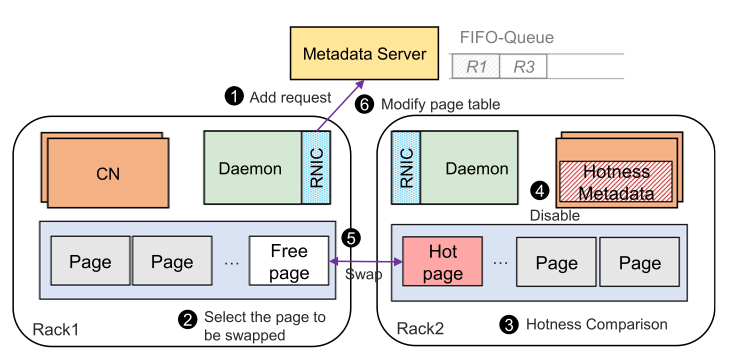
Rcmp는 기존 페이지 기반의 메커니즘이 페이지 폴트를 이용하여 스왑 매커니즘을 수행한 것과 다르게 user-level swap mechanism을 사용한다. Rcmp의 hot 페이지 스왑 알고리즘을 아래의 절차를 따른다.
- R1의 스왑 요청이 MS의 FIFO 큐에 큐잉된다.
- R1은 스왑 될 free page를 선택한다. Free page가 없다면, cold page를 선택한다. Cold page도 없다면, 6단계로 넘어간다.
- R2는 스왑될 페이지들의 hotness를 R1의 hotness와 비교한다. R2의 hotness가 더 높으면 swap을 거부한다. Read hot인 경우에는 R1의 CXL에 캐싱한다. 캐싱된 페이지는 read-only이며, write 될 때 삭제된다.
- R2의 스왑될 페이지의 metadata에 대해 disable 하고 page table을 업데이트한다.
- Hot page를 one-sided RDMA를 통해 스왑 한다.
- R1의 page table을 업데이트하고, MS의 요청을 dequeue 한다.
3-3. RRPC
Rcmp에서 진행한 RPC와 hybrid(RPC + one-sided RDMA)의 throughput 비교 실험에서 512B를 기준으로, 데이터의 사이즈가 512B보다 작을 때는 hybrid 방식보다 RPC의 처리량이 더욱 높은 것으로 나타났다.
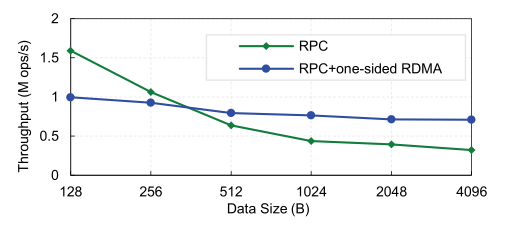
이런 특성을 이용하여 Rcmp에서는 데이터의 사이즈를 기준으로 전송 방식을 바꿔가며 communication을 수행하여 throughput을 올리는 framework를 제시하였다. 데이터 사이즈에 따른 전송 방식은 아래와 같다.
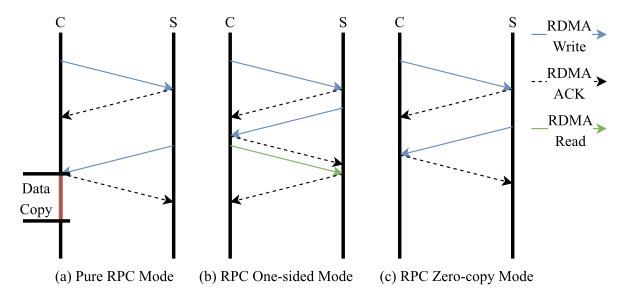
- Pure RPC mode: 512B보다 작은 데이터의 communication에 사용 (데이터 요청 -> 데이터 반환)
- RPC and one-sided mode: unstructred big data의 communication에 사용 (주소 요청 -> 사이즈 전달 -> RDMA read)
- RPC zero-copy mode: structured big data의 communication에 사용 (데이터 요청 -> RDMA write)
'논문 > 메모리 분리' 카테고리의 다른 글
| TPP - ASPLOS'23 (1) | 2024.03.19 |
|---|---|
| POND - ASPLOS'23 (0) | 2024.02.26 |