Achieving Microsecond-Scale Resource Fungibility with Logical Process
Authors: Zhenyuan Ruan, Seo Jin Park, Marcos K. Aguilera, Adam Belay, Malte Schwarzkopf
Groups: MIT, VMware Research, Brown Univerisity
Keywords:
Datacenter, Resource Fungibility
#1 Motivation
1-1. Resource Fungibility
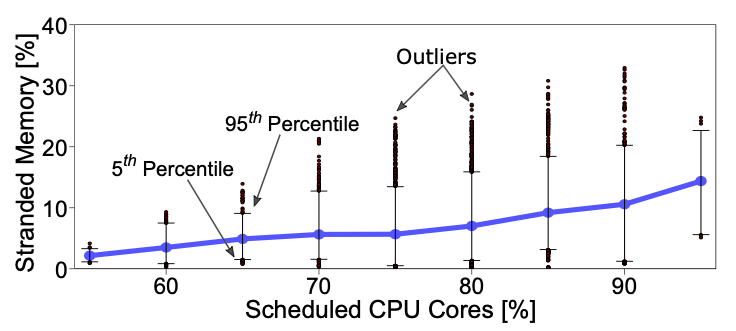
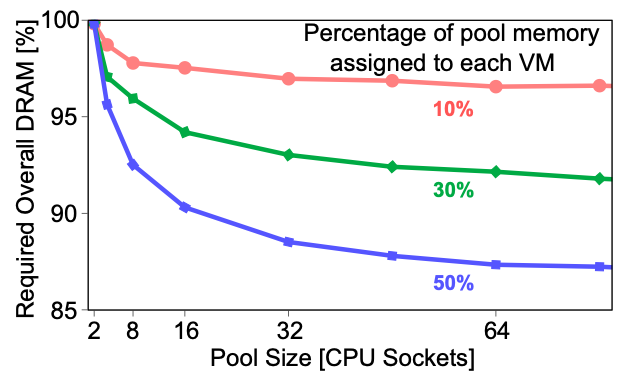
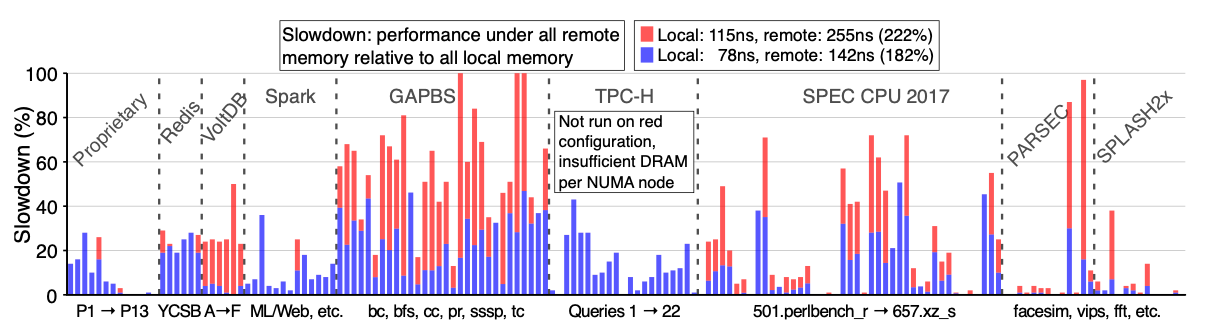
현재의 클라우드 시스템에서 인스턴스를 할당하는 방식에는 Resource Fungibility 오버헤드가 있다. 클라우드 컴퓨팅에서 사용자는 고정된 크기(코어의 수, 메모리 등)의 인스턴스를 요청하고, Provider는 bin-pakcing 알고리즘에 의하여 해당 인스턴스를 할당 가능한 서버에 할당한다. 사용자 입장에서 인스턴스의 크기는 고정되어 있기 때문에 실제 어플리케이션의 자원 사용량과는 다르며 남는 자원들은 대부분 유휴 상태로 존재한다. Provider는 낭비된 자원을 활용하여 다른 인스턴스에 할당하여 자원을 효율적으로 사용하려고 한다. 하지만 이러한 방식은 시스템에 간헐적으로 과부하가 발생하여 성능 저하가 발생할 수 있으며, 이는 지연 시간에 민감한 워크로드에 특히 문제가 된다. 이와 같은 문제의 이유는 인스턴스를 할당하는 단위가 너무 크기 때문이다. 따라서 클라우드의 효율적인 디자인은 disruption을 피하고 자원을 작은 단위로 빠르게 재할당 할 수 있어야 한다.

본 논문에서는 resource fungibility를 해결하기 위해 논리 프로세스라는 개념을 제안한다. 논리 프로세스는 논리 디스크의 개념에서 착안한 방식으로 proclet이라는 단위로 논리 프로세스를 결합하지만 물리 자원들은 여러 머신에 걸쳐 분배하는 개념을 말한다. Proclets으로 분리된 프로세스는 fine-grained이기 때문에 자원을 비효율적으로 할당하는 비율이 적으며, 전체 프로세스를 마이그레이션 하는 것에 비해 마이그레이션이 매우 빠르다.
1-2. Alternative approaches
논리 프로세스와 비교하여 fungibility를 해결할 수 있는 다른 방식들은 다음과 같은 단점들을 가진다.
- Migrate VM, containers, or process: 마이그레이션이 느리다.
- Process abstraction: 마이그레이션 문제를 해결 했으나 공유 메모리의 캐시 일관성 오버헤드가 있다.
- PGAS: 캐시 일관성 오버헤드를 해결 했으나 병렬 어플리케이션에만 적용 가능하다.
- Distributed object, microservices, and serverless funtions: coarse-grained instance 오버헤드, RPC 오버헤드가 있다.
- Parallel programming frameworks: 데이터가 정적으로 위치해야 한다.
- Far memory system: 원격 메모리가 cold일 때만 효율적이다. (stateless or read-only service에서 효율적임)
#2 The Logical Process Abstraction
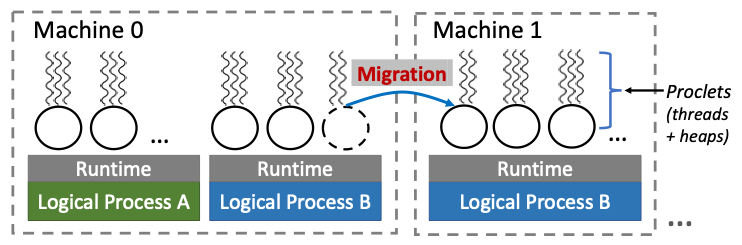
Proclet은 하나의 힙과 공유 메모리를 통해 힙에 동시 접근할 수 있는 여러 스레드로 이루어져 있다. 힙 메모리는 직접적으로 공유되는 것이 아닌 논리 객체에 대한 포인터를 힙에 저장하고 있는 루트를 통해 공유된다. 이러한 방식은 개발자가 object-oriented 방식을 통해 proclet을 개발할 수 있도록 한다.
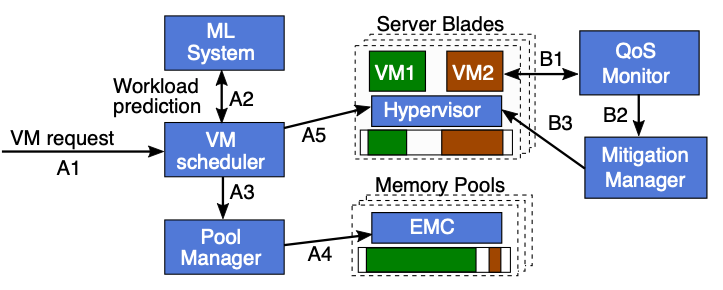
논리 프로세스가 할당된 머신의 수는 이용가능 한 수의 머신의 수에 따라 계속해서 바뀌며, 각 머신들은 각각의 런타임에 의하여 논리 프로세스를 처리한다. 런타임은 proclets 간의 location-trasparent communication을 제공하며 외에도 추가로 resource pressure detection, proclets migration between machines, and failures handling 기능을 제공한다.
논리 프로세스를 개발하는 것은 UNIX 프로세스를 개발하는 것과 같으며 차이점은 2가지가 존재한다. 첫째로 개발자는 상태를 proclet 단위로 분리해야 하고, 두번째로 proclet API를 사용하여야 한다.
2-1. Address spaces and Cache coherence
논리 프로세스는 마이그레이션 후 swizzling 없이도 머신 간의 포인터를 유효하게 사용하기 위해 각 머신에 동일한 주소 공간 레이아웃을 사용한다. 그리고 런타임 인스턴스가 초기화 및 새로운 proclet 생성 시 레이아웃의 동기화를 유지하는 역할을 한다.

위 그림은 주소 공간 레이아웃의 예제이다. Read-only 코드와 데이터 세그먼트는 모든 머신에 매핑되어 있다. 그렇기 때문에 모든 머신은 binary-compatible 해야 한다. Read-only 데이터는 정적 배열, 테이블, proclet의 인풋과 같은 데이터를 저장하는 역할을 한다. 반면에 proclet의 힙은 실행 중 하나의 머신에서만 매핑되며, 다른 프로세스는 접근할 수 없다. 이는 머신 간 캐시 일관성을 보장해야 하는 공유 메모리 구조보다 효율적이다. 이 구조에서 데이터를 교환하기 위해서는 같은 머신 내에서는 function call 외부에서는 RPC call을 이용한다. 또한 메모리를 공유하지 않기 때문에 fault isolation이 가능하다.
2-2. Programming Model
개발자는 proclet root class를 통해 어플리케이션을 작성하여야 한다. 기존의 오브젝트 기반 프로그래밍처럼 각 클래스는 메소드와 필드를 정의하며, 메소드 구현은 어플리케이션의 로직을 구현하고 API를 통해 proclet을 호출할 수 있다. 필드는 proclet 내부의 상태를 정의하며 정적 및 동적 모두 할당할 수 있다.

논리 프로세스는 main proclet에서부터 시작한다. main proclet은 make_proclet 함수를 통해 다른 proclet을 생성할 수 있다(line 10~11). proclet은 원격 메소드 호출 및 클로저를 통해 소통할 수 있다. 메소드 호출에서는 다른 proclet의 root proclet의 메소드를 Run() 함수 또는 RunAsyunc() 함수를 이용하여 호출한다(line 13 and 17~18). 클로저에서는 proclet을 function shipping을 통해 구현하고, 다른 proclet의 루트 객체에 함수를 ship한다(line 15). 또한 원격 런타임이 로컬 런타임과 동일한 proclet의 메소드나 클로저를 실행할 수 있기 때문에 val를 보호하기 위한 뮤텍스 mu 또한 필요하다(line 5).
논리 프로세스는 POSIX나 I/O abstraction이 아닌 런타임이 제공하는 abstraction을 사용하여 I/O를 수행한다. 이를 통해 proclet이 머신에 독립적이며, TCP 상태와 같은 로컬 커널 상태를 전달하지 않고도 머신 간의 마이그레이션이 가능하다. 런타임이 TCP 연결을 유지하기 때문에 논리 프로세스의 특정 proclet과의 연결이 가능하다.
2-3. Porting Applications to Logical Processes
상태를 fine-grained 유닛으로 분리할 수 있는 어플리케이션들은 각각의 상태가 proclet으로 변환되는 방식으로 모두 논리 프로세스로 포팅이 가능하다. 이러한 특징은 이미 microservice나 FaaS와 같이 상태를 분리한 클라우드 어플리케이션에 적합하다.
논리 프로세스를 proclet으로 나눌 때 granularity와 scope 두 가지를 고려해야 한다. Proclet의 사이즈가 너무 크면 resource fungibility가 다시 발생하며, 사이즈가 너무 작으면 통신 오버헤드가 크다. 실험적인 결과를 통해 수 MiB 상태 크기를 가지는 proclets이 가장 잘 동작하였다. Proclet에 어떤 기능을 구현할 지도 중요한 문제인데 한 가지 방법으로는 하나의 proclet을 모듈이나 mircoservice, 패키지와 같은 논리적 함수 유닛으로 분리하는 functional splitting이 있고, 다른 방법으로는 함수 유닛의 크기가 일반적인 proclet의 크기보다 크기 때문에 이를 분리하는 sharding이 있다.
2-4 Fault Tolerance
Proclet은 복사를 통해 fault tolerance를 허용한다. 복사된 proclet은 원본 proclet의 힙을 복사하여 유지하며, 이 백업은 런타임에 의해 다른 머신에 같은 가상 주소로 위치하게 된다. 백업 힙을 동기화 상태로 유지하기 위해, 런타임은 원본 proclet의 호출 요청을 정렬하여 복사 proclet에 전달한다. 복사 지연 시간을 줄이기 위해 원본 proclet과 백업 proclet이 중복 실행되지만 원본 proclet은 복사 작업이 완료되어야 호출을 완료한다. 시스템이 원본 proclet의 장애를 감지하면, atomic 하게 proclet의 백업을 발생 시킨다. 또한 동일한 힙을 유지하기 위해, proclet을 일시 중지하여 새로운 백업을 추가하고, 새로운 proclet에서 백업 레플리카로 힙을 복사한다.
#3 Nu Runtime System
Nu 런타임은 논리 프로세스 추상화를 제공하며 Linux 환경에서 동작한다. Caladan 위에 Nu를 구현하였는데 그 이유는 Caladan이 work-stealing 방식으로 낮은 지연 시간의 user-level threading 패키지와 kernel-bypass, user-level TCP/IP를 제공하기 때문이다. 예를 들어, 스레드가 블락되어 있을 때 Caladan이 낮은 오버헤드로 컨텍스트 스위칭을 잘한다.
Nu는 Caladan에 10,000줄가량의 C++ 코드를 추가하여 구현되었으며, 이는 infrastructure 간의 효율적인 통신과 여러 힙을 처리하기 위한 새로운 메모리 관리 방법, 최적화된 proclet 마이그레이션 시스템, proclet의 위치를 트래킹 하는 컨트롤러를 포함한다.
3-1. Serialization and Communication
Nu는 원격 호출을 정렬하기 위해 cereal을 사용한다. Cereal은 대부분의 STL type을 지원하는 binary serialization을 제공하며, 포인터와 참조에 대한 직접 접근을 금지한다. Nu는 cereald을 수정하여 함수와 proclet 포인터를 정렬한다. Nu는 코드 일반화가 필요한 RPC와 대조적으로 원격 호출을 정렬화하기 위해 컴파일 시 C++ 템플릿을 사용한다. 따라서 개발자는 boilerplate 없이 원격 메소드를 호출할 수 있으며, 정적 타입 검사까지 제공한다.
??
3-2. Memory Management
Nu는 proclet의 힙을 관리하기 위해 확장성을 위한 코어 당 캐시와 멀티코어 메모리 할당자를 포함하는 커스텀 slab allocator를 사용한다. C++에서 custom new()가 사용가능한 점을 이용하여 메모리 할당자를 구현하였다. Nu는 각 스레드가 어떤 프로클릿과 연관되어 있는지 추적하고 할당을 올바른 힙으로 유도한다.
3-3. Migration
Proclet을 마이그레이션 하기 위해 런타임은 migration flag를 설정한다. 그다음 proclet을 실행 중인 스레드를 정지하고 레지스터의 상태를 저장한다. 그런 다음 proclet의 data(힙, 스택, 레지스터 상태)를 새로운 목적지로 전달한다. 마지막으로 런타임은 migration flag를 초기화하고 컨트롤러에 proclet의 위치를 업데이트한다.
Nu는 migration datapath를 최적화하였는데, 먼저 TCP throughput을 개선하기 위해 parallel connedction과 jumbo frame을 사용하였다. 기존에 병목점이었던 linux mmap을 pre-zero freed page로 수정하여 라인 당 100 GbE의 throughput을 달성하였으며, 이전의 frame allocator를 재사용하기 위해 mremap을 수행하였다.
Nu는 어떤 proclet을 옮겨야 하고 어디로 옮겨야 할지 정하는 확장 가능한 마이그레이션 정책을 제공한다. CPU load나 cache pressure, memory capacity, memory bandwidth 등과 같은 요소들을 고려할 수 있으며 proclet의 locality를 향상하기 위해 동시에 고려할 수 있다.
Nu의 마이그레이션이 충분히 빠르기 때문에 단순한 정책도 잘 동작한다. 특히 자원이 부족한 상황에서 어떤 자원을 소모할지 예측하는 정교한 알고리즘을 사용하지 않고 단순히 마이그레이션 시켜도 성능이 잘 나온다. 마이그레이션이 언제 필요한 지 정하기 위해 모니터링 스레드가 계속해서 자원의 소모량을 측정한다.
Nu는 resource pressure가 없어질 때까지 한 번에 하나의 proclet을 마이그레이션 한다. 어떤 proclet을 마이그레이션 할 지 결정하기 위해 Nu는 아래의 식을 사용한다.

RESOURCE_USE는 proclet의 자원 소모량을 나타내고, MIGRATION_TIME은 해당 proclet의 힙 사이즈를 고려한 마이그레이션 시간을 나타낸다. 이 식은 resource pressure 완화 속도를 극대화하고 Nu가 응답 속도를 최적화한다. 런타임은 이 속도를 추정하기 위해 실시간으로 메트릭을 수집한다. 마이그레이션 대상을 결정하기 위해 Nu는 전역 클러스터 컨트롤러에 쿼리 하고, 컨트롤러는 서버 간의 리소스 사용량을 모니터링하고 가능한 대상을 반환한다.
3-4. Controller
Nu는 proclet placement나 가상 주소 공간 할당과 같은 클러스터 간의 결정 및 proclet의 위치나 자원 사용량과 같은 정보를 트래킹을 위한 컨트롤러가 있다. 컨트롤러가 중앙 처리 방식을 띄지만 프라이머리 백업 복제나 단순 리커버리와 같은 방식으로 높은 이용가능성을 보인다.
컨트롤러는 주기적으로 서버의 이용 가능한 자원을 측정하며, 이것을 이용하여 proclet의 생성 및 마이그레이션 위치를 정한다. proclet은 중복되지 않는 가상 주소 공간을 사용하여야 한다. 따라서 Nu는 가상 주소 공간을 4GB의 세그먼트 배열로 나누어 proclet의 힙 공간을 확보해 둔다. 컨트롤러는 할당된 세그먼트와 할당되지 않은 세그먼트 리스트를 유지하여, proclet을 할당할 때 로컬 런타임에게 할당되지 않은 세그먼트를 전달한다.
컨트롤러는 각 proclet의 시작 논리 주소로부터 위치를 유지하고, 각 런타임은 proclet이 최근 접근한 캐시를 유지한다. 이것은 컨트롤러를 임계영역에서 제거함으로써 컨트롤러와의 통신을 위한 메소드 호출을 제거한다. Proclet을 마이그레이션 할 때, 컨트롤러는 매핑을 업데이트한다. 이로 인해 캐시가 오래되어 로컬 런타임에서 잘못된 시스템으로 메서드 호출을 보낼 수 있다. 이것이 발생하면 원격 머신은 에러를 반환하게 되는데, 로컬 머신은 해당 캐시 엔트리를 invalidating 하고 새로운 머신을 찾음으로써 에러를 처리한다.
3-5. Replication
Nu에서는 프라이머리를 백업하기 위해 연산을 복제본에 포워딩하고 있다. 이때 서브 연산이 발생하는 경우, 프라이머리와 복제본 두 곳에서 연산이 발생할 수 있기 때문에 유의하여야 하는데, Nu는 RIFL의 복제 감지를 이용하여 이를 해결하였다. 각 proclet 간의 호출에서 서브 연산이 발생하면 프라이머리가 서브 연산의 결과를 복제본에 전달하는 방식으로 복제본은 서브 연산을 재실행하지 않고 결과를 재사용한다.
컨트롤러가 실패된 프라이머리를 감지하면, 복제본이 새로운 프라이머리가 되도록 하고 위치 매핑을 새로운 프라이머리로 업데이트한다. 하지만 런타임은 오래된 프라이머리를 가지고 있게 되는데, 이를 epoch-based 방식으로 해결한다.
'논문 > 네트워크 & 시스템' 카테고리의 다른 글
| Junction - NSDI'24 (0) | 2024.06.20 |
|---|---|
| CC-NIC - ASPLOS'24 (0) | 2024.04.26 |