CXL-Based Memory Pooling Systems for Cloud Platforms
Authors: Huaicheng Li, Danel S. Berger, Lisa Hsu, etc
Groups: Carnegie Mellon University, Microsoft Azure, Intel, Stone, Google
Keywords: Memory Disaggregation, CXL, Memory Pooling, ML
#1 Background
논문에서는 클라우드 환경에서 성능과 비용의 중요 요소인 메인 메모리에 대한 stranded memory와 untouched memory 문제를 지적하며, 이를 CXL을 활용한 메모리 풀링으로 해결하고자 한다.
1-1. Stranded and untouched memory
기존의 가상 머신의 자원 할당 방식은 서버의 메모리를 가상 머신의 NUMA 노드에 정적으로 할당하는 방식이었다. 이런 방식은 두 가지 메모리 낭비를 초래하였다.
- Stranded Memory(남는 메모리): 서버의 CPU는 가상 머신에 모두 할당되었지만 아직 할당되지 않고 남아있는 서버의 메모리
- Untouched Memory(미사용 메모리): 가상 머신에 할당된 메모리 중에서 가상 머신이 실제로 사용하지 않고 남아 있는 메모리

1-2. CXL
Compute Express Link(CXL)은 CPU와 여러 디바이스(가속기, 메모리 등) 간의 메모리 공유를 위한 프로토콜을 제공하는 고성능 인터페이스이다. PCIe 5.0 interface에서 flexbus를 제공하는 CPU에 한하여 사용이 가능하며, CXL.cache 프로토콜을 통해 캐시 일관성까지 제공한다.
최근 메모리 분리 연구와 관련하여 기존의 RDMA 방식과 다르게 CXL은 PCIe를 사용하여 latency 이득이 매우 크기 때문에 CXL을 사용하려는 움직임이 많으며, 해당 논문에서도 CXL을 통한 메모리 분리를 이용하여 memory stranding 문제를 해결하려 한다.
#2. Motivation Experiments
아래에서부터는 Microsoft Azure에서 실시한 memory stranding 및 untouched memory 측정 및 관련 워크로드 성능, CXL latency 등을 분석해 볼 것이다. 그리고 이를 통해, POND의 설계 방향을 이해할 수 있다.
2-1. Memory stranding
그림 3은 호스트 가상 머신에 스케줄링된 코어 별 stranded DRAM bucket의 분포 측정의 snapshot이다. 파란 선은 stranded memory 비율의 평균값을 나타내며, 85% 이상의 코어가 가상머신에 할당되면 평균값이 10%까지 증가하게 된다. 또한, 95% percentile에서 최댓값이 35%까지 증가하는 모습을 보인다.
그림 4는 VM-to-server 트레이스를 분석하여, 풀링을 통해 절약할 수 있는 DRAM의 양을 나타낸 것이다. Pool size는 같은 DRAM이 접근할 수 있는 CPU 소켓을 뜻하며, pool size가 커질수록 풀링을 통해 절약할 수 있는 DRAM의 양이 적어진다. 하지만 이 부분은 메모리 풀의 사이즈가 커지면 감소하는데, 아래 그림에서 10%의 메모리 풀을 제공하였을 때 32개의 소켓으로는 12%의 DRAM을 save 할 수 있으나 64개의 소켓에서는 13%의 DRAM을 save 할 수 있다.
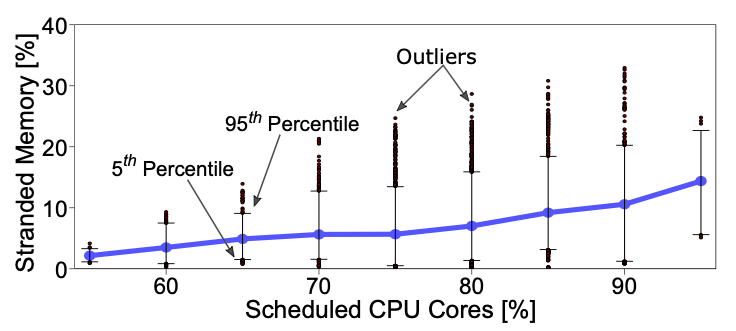
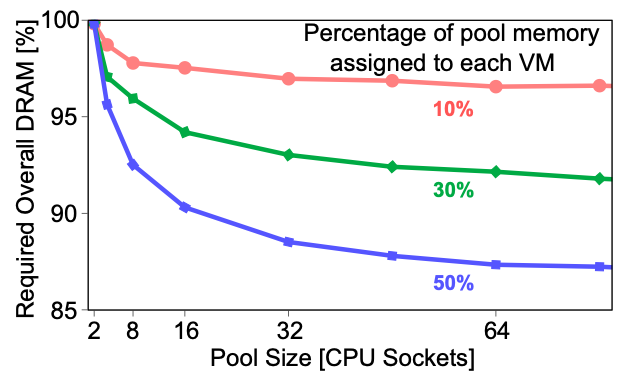
위의 실험들을 요약하면, 서버에서 가상 머신에 할당되는 코어의 수가 많아질수록 stranded memory의 비율을 늘어나며 이는 최대 35%까지 달한다. 하지만 실험적인 분석에서 메모리 풀을 통해 DRAM을 save 할 수 있는 결과가 나왔는데, 50% 메모리 풀을 제공할 때 32개의 소켓에서 12%까지 DRAM을 save 할 수 있었다. 이 사실을 바탕으로 POND에서는 CXL memory pool을 stranded memory 및 untouched memory을 위해 제공하여 DRAM의 효율을 증가시키려 한다.
2-2. Workload sesitivity
CXL은 로컬 DRAM보다 접근 latency가 느리기 때문에 이에 따른 워크로드의 성능 저하가 있을 수 있다. 이를 관찰하기 위해 Azure에서는 158개의 워크로드에 대해 CXL latency가 로컬 DRAM보다 182% 느릴 때, 222% 느릴 때로 가정하여 실험을 진행하였다. 아래 그림 5에서 보이다시피, latency가 182% 증가하였을 때 latency에 민감하지 않은 워크로드는 성능 저하가 없기도 한 반면, 민감한 워크로드의 경우 25% 이상 성능이 감소하기도 한다.
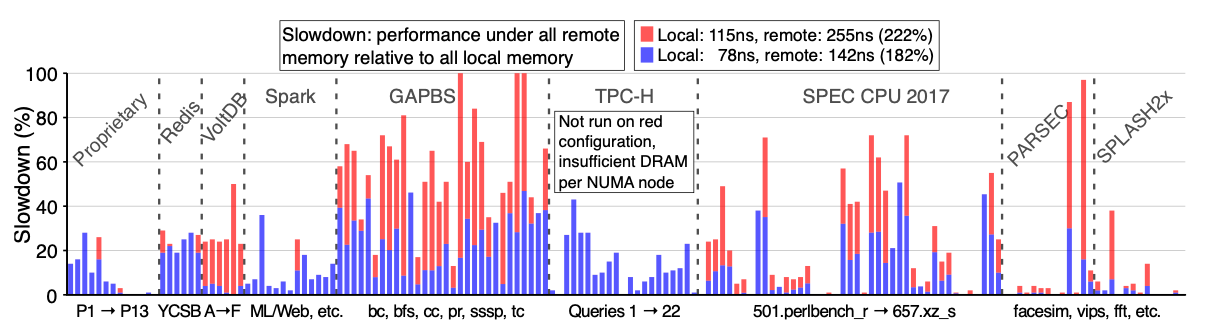
위 실험을 통해 latency에 민감하지 않은 워크로드에 대해 CXL 메모리 풀을 활용하여 자원 효율을 높이는 설계가 가능함을 확인할 수 있다.
#3 POND
3-1. Control plane layer
POND는 아래 그림 6에서처럼 두 가지 역할을 한다. 풀 메모리를 얼마나 사용할 지 예측하고 할당하는 VM scheduler와 가상 머신의 성능을 계속해서 파악하고, 이에 따라 CXL 메모리 풀의 양을 조절하는 QoS Monitor 두 가지가 있다.
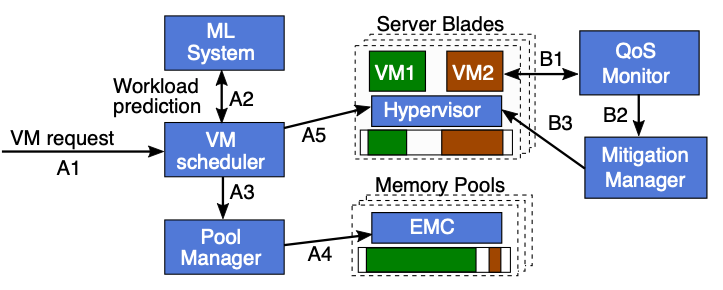
- Prediction and VM scheduling
- A1: VM request arrives.
- A2: Queries model for a local memory prediction.
- A3: Informs PM about needs.
- A4: Memory onlining and allocating.
- A5: Informs Hypervisor to start VM.
- QoS Monitoring
- B1: Queries hypervisor and hardware performance counters &
Uses an ML model of latency sensitivity. - B2: If performance impact exceeds the PDM, ask Mitigate Manager to trigger a memory reconfiguration.
- B3: Do memory reconfiguration. (after reconfiguration, VM uses only local memory)
- B1: Queries hypervisor and hardware performance counters &
3-2. Prediction models
- Prediction for VM scheduling
(추가 예정)
- QoS Monitoring
(추가 예정)
3-3. Software layer
Software layer에서 하는 주요한 역할은 풀 메모리의 할당 및 해제, 프레그멘테이션 방지, 풀 메모리 가상 머신에게 전달 그리고 opaque 가상 머신을 위한 Telemetry이다.
- Pool memory ownership
풀 메모리 할당은 호스트 드라이버에게 인터럽트를 트리거시켜 드라이버가 hot-plugged 될 범위의 주소를 읽도록 한다. 이후 드라이버는 OS의 Memory Manager가 해당 메모리 슬라이스를 online으로 요청하도록 하고, EMC가 호스트의 메모리 슬라이스에 대한 접근 권한을 부여한다. 풀 메모리 할당 해제는 호스트가 메모리 슬라이스를 offlining 후 EMC에서 메모리 슬라이스의 권한을 해제하여 완료한다.
POND는 가상 머신이 시작되거나 종료될 때 발생하는 프레그멘테이션을 방지하기 위해 메모리 슬라이스가 1GB 단위로 가상 머신에 할당되며, 다른 호스트에게 재할당되기 전에 free 및 offline 상태로 보관함으로써 프레그멘테이션을 방지한다. 그러나 호스트나 드라이버가 풀 메모리를 할당하여 프레그멘테이션을 유발할 수 있기 때문에, 하이퍼바이저만 사용 가능한 메모리 파티션을 할당하고, 호스트와 드라이버는 호스트 로컬 메모리 파티션에서 메모리를 할당하여 호스트나 드라이버에 의한 프레그멘테이션을 방지한다.
이러한 최적화들을 통해, 1GB 메모리 슬라이스를 offlining 하는 데에 10~100ms 소모되고, onlining은 1us 소모된다. 이때 메모리 onlining은 충분히 빠르기 때문에 가상 머신을 시작하는 데에 있어 block이 되지 않지만, offlining은 너무 느리기 때문에 critical path에서 발생하면 안 된다. 따라서 POND는 항상 할당되지 않은 풀 메모리를 보관하는 버퍼를 유지하여 이를 해결하였다.
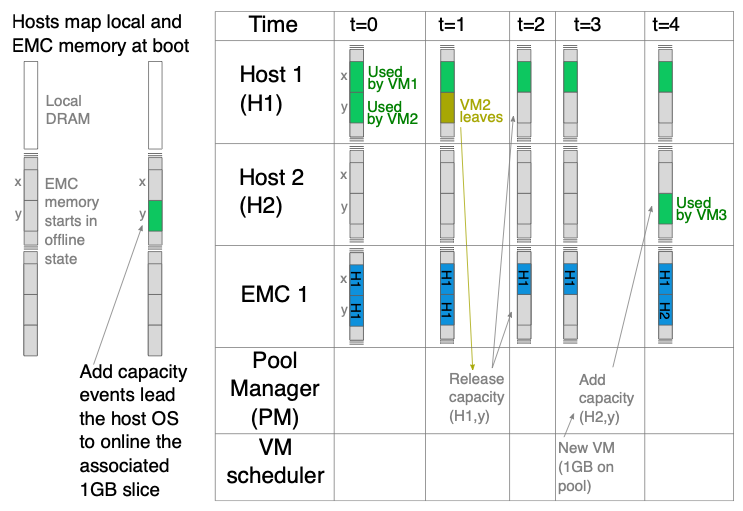
- Exposing pool memory to VMs
NUMA-local 메모리와 풀 메모리를 사용하는 가상 머신은 풀 메모리를 zNUMA 노드로 취급한다. 그래서 가상 머신을 시작할 때 cpu 항목이 없는 메모리 블록을 추가하여 zNUMA 노드를 생성하며, zNUMA 노드의 크기가 untouched memory의 크기와 같으면 가상 머신은 로컬 메모리에서만 동작하게 된다.
- Reconfiguration of memory allocation
가속기와의 호환성을 유지하기 위해 로컬 및 풀 메모리 매핑은 일반적으로 가상 머신의 lifetime 동안 static mapping 상태를 유지한다. 그러나 가상 머신의 메모리 할당이 최적이 아닐 때, POND는 메모리 할당을 재정의 한다. 호스트에 로컬 메모리를 사용할 수 있는 경우, 가속기를 사용하지 않도록 설정하고 가상 머신의 모든 메모리를 로컬 메모리로 복사한 다음 가속기를 다시 사용하도록 설정한다. 이를 통해 로컬 및 풀 메모리 할당을 초기화하며, 풀 메모리 1GB마다 약 50ms가 소요된다.
- Telemetry for opaque VMs
POND는 두 가지 유형의 가상 머신 Telemetry를 측정한다. 첫째로, Pond는 메모리 성능과 관련된 하드웨어 카운터를 수집하기 위해 PMU(Performance Measurement Unit)를 사용하고, 분석을 위해 TMA(Top-down Method for Analysis)를 사용한다. 그리고 하이퍼바이저를 수정하여 메트릭을 개별 가상 머신에 연관시키고 가상 머신 카운터 샘플을 분산 데이터베이스에 기록한다. 모든 코어 PMU 메트릭은 간단한 하드웨어 카운터를 사용하여 오버헤드를 유발하지 않는다.

둘째로, 가상 머신의 untouched memory page를 추적하기 위해 하이퍼바이저 Telemetry를 사용한다. 게스트에 할당된 메모리를 추적하는 기존 카운터를 사용하며, 이는 사용된 메모리를 과대 평가하는 경향이 있다. 그리고 하이퍼바이저 페이지 테이블에서 액세스 비트를 스캔하여 untouched memory page를 찾는다. POND는 untouched memory page만 찾기 때문에 페이지 테이블의 액세스 비트를 자주 리셋할 필요가 없으며, 이는 오버헤드를 최소화한다.
3-4. Hardware layer
Pond는 여러 호스트에게 공유되는 메모리 풀을 제공하며, 여러 포트를 통해 풀 내의 호스트에게 각각의 캐시 일관성 도메인과 별도의 하이퍼 바이저를 제공한다. 또한 호스트 간의 명시적인 소유권 모델을 통해 호스트의 독립적인 메모리 풀을 보장한다. 호스트는 처음에 제공 받은 풀 메모리를 offline으로 취급하다가 호스트의 수요에 따라 1GB 메모리 슬라이스를 동적으로 할당하며, 각 슬라이스는 주어진 시간에 하나의 호스트에게 할당된다. EMC는 캐시라인의 슬라이스 요청자와 소유자가 일치하는지 여부를 검사하여 슬라이스를 동적으로 할당하며, 액세스가 허용되지 않으면 메모리 오류가 발생한다.
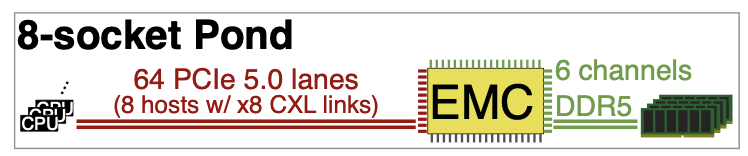
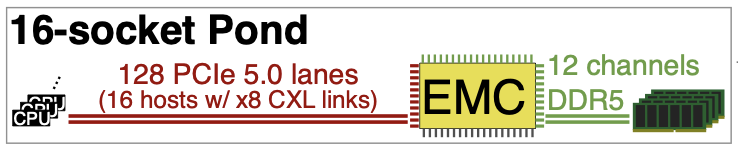
CXL의 지연 시간은 CXL 포트, CXL retimer 및 CXL 스위치 지연 시간이 대부분이며, 아래 그림 7과 같다. (CXL retimer는 각 방향에 지연 시간을 추가하여 CXL/PCIe 신호 무결성을 유지하고 사용되는 장치이다.)

출처
- 그림 1: https://pmem.io/blog/2022/01/disaggregated-memory-in-pursuit-of-scale-and-efficiency/
Disaggregated Memory - In pursuit of scale and efficiency
A software person perspective on new upcoming interconnect technologies. Existing Server Landscape Servers are expensive. And difficult to maintain properly. That’s why most people turn to the public cloud for their hosting and computing needs. Dynamic v
pmem.io
- 그림 2: CXL specification
- 그림 3, 4, 5: POND - NSDI'23
'논문 > 메모리 분리' 카테고리의 다른 글
| Rcmp - TACO'24 (0) | 2024.04.22 |
|---|---|
| TPP - ASPLOS'23 (1) | 2024.03.19 |